BigQuery でさまざまな情報が JSON 形式で格納されているテーブルはありませんか? MoT でも JSON 形式でログ情報を格納しているテーブルが存在します。そのようなテーブルの難点と、難点を克服するためのエンジニアリングについて紹介します。
AI技術開発部アルゴリズムグループの老木です。本記事は、BigQuery Advent Calendar 2021 の 1日目の記事です。
テーブルのSTRING型の列に JSON データを埋め込むのは強力なソリューションです。JSONを用いることで得られるメリットとして、
があります。MoT では一部のログテーブルで JSON が埋め込まれた列が存在します。
しかし、これらのメリットは主にテーブルを書き出す側のものです。テーブルの利用者にとってJSON 列は、
- スキーマから何が格納されているかわからない
- パースのための json_value をいちいち書くのがしんどい
- JSON のパース処理が入るためクエリが重くなりがち
- JSON 列の一部フィールドのみを読み込めないため、利用料金が上昇する
といったデメリットがあります。
本稿では、JSON フィールドを持つログテーブルを利用しやすくするために行った、View や Materialized View を用いたエンジニアリングについて紹介します。
JSON 列のパース
以下のような JSON がテーブルの payload 列に入っているものとします。
{ "single": 10, "list": [1,2,3], "composite": { "elem": 3 } }
この payload 列から値を取り出すには、json_value や json_value_array を利用します。ログを解析するたびに、以下のようなクエリを記述するのは面倒です。また、single フィールドにのみアクセスしようとしても、payload 列全体が読み込まれてしまい処理時間や利用料金が上昇します。
select cast(json_value(payload, "$.single") as int64) as single, array( select cast(l as int64) from unnest(json_value_array(payload, "$.list")) as l ) as list, struct( cast(json_value(payload, "$.composite.elem") as int64) as elem ) as composite, from research_oiki_json.json_sample
解決の方向性
このログテーブルへのアクセス簡略化のために、以下の 4 案が考えられました。
- ログ出力を行うサーバー側を改修し、JSON フィールドを含まないスキーマにする
- JSON 列をパースして新しいテーブルに詰め直すクエリを作成する。airflow や scheduled query からクエリを定期実行することで、元テーブルと同期させる。
- View を使ってより良いスキーマを定義する
- Materialized View を使ってより良いスキーマを定義する
1 は理想的なプランです。しかし、サーバー側の改修や既存データの移行は軽い気持ちで行える作業ではありません。
2 も良いプランです。理想的なテーブルが作れるので、元テーブルの cluster や partition の設定が不適切でも、正しく指定しなおすことも可能です。一方で、airflow や scheduled query によるクエリの定期実行が必要となり、管理コストが生じます。また、元テーブルにデータが追加された際に、それを反映するまでのタイムラグが大きくなりがちです。更新までのタイムラグが大きいテーブルが増えると、テーブル間の依存関係の管理コストが増大する問題も生じます。
2 を適用しているログテーブルもあるのですが、より低コストな解決策を求めて 3, 4 について詳しく見ていきます。
View を使ってより良いスキーマを定義する
JSON をパース済みの View を提供することで、これまで課題となっていた項目のいくつかは解決します。以下のような View があれば、利用者は View を通じて簡単に single フィールドにアクセスできます。
create or replace view parse_view as select cast(json_value(payload, "$.single") as int64) as single, from research_oiki_json.json_sample
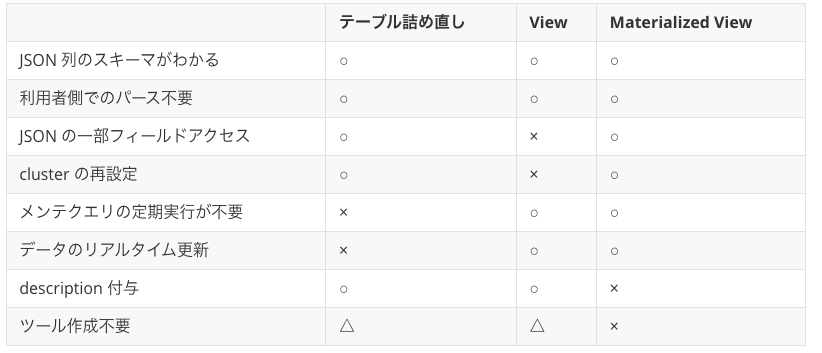
View によって課題の解決状況は下表のようになります。新しいテーブルへの詰め直しと比較して、一部のフィールドへのアクセスが出来ませんが、管理コストが低下することがわかります。

JSON の parse
View の利用者は JSON の parse から解放されました。しかし View を作る側は JSON の parse から逃れられていません。JSON 列を持つログテーブルは数十あり、JSON 列はネストされた数十のフィールドを持つことがあります。この JSON の要素を一つ一つ json_value するのは、かなりの手間です。
そこで、よく使われるテクニックが以下のような javascript UDF の利用です。UDF の型定義さえ行えば、"JSON.parse(s)" だけですべてのフィールドのパースが行えます。
CREATE OR REPLACE FUNCTION {{dataset}}.parse_json_example(s STRING) RETURNS STRUCT < result ARRAY< STRUCT< request_unix_time INT64, error_msg STRING > > err_msg STRING, api_version STRING > LANGUAGE js AS "return JSON.parse(s);";
項目名が増えると、型定義も大変になってきます。そこで、JSON ファイルから javascript UDF を生成するツールを作成しています。このツールは、BigQuery に JSON をスキーマの自動検出モードを ON にしてアップロードし、作成されたテーブルのスキーマを取得することで、型定義を自動生成します。
description 管理
テーブルのスキーマの各列に description があると、列が何を意味するかを正しく利用者に伝えることができます。

我々のチームでは、テーブルへの descriptoin 付与は SQL から行っています。
create table if not exists sample_table ( ts timestamp options(description="リクエスト作成時間"), car_request_id int64 options(description="リクエストID"), );
View でも同様に列への description を記述したいのですが、2021/11/16 現在、SQL 上では View の description を記述することはできず、API か ウェブコンソールからのみ description を記述できます。
description の管理を SQL ファイル上で行うために、コメントに description を記述すると、反映するツールを作成しています。以下のようにコメントに yaml 形式で description を埋め込んでいます。
/* @description_start ts : 予約を申し込んだ時刻 reservation_request_id : 予約ID @description_end */ create or replace view sample_view as select * from base;
View まとめ
View によるスキーマの定義は、利用者の利便性を確保できる上に、かかるコストは非常に低くお勧めできる方法です。煩雑なパースコードを書く手間もツールで軽減することができます。
一方で、クエリの実行速度の観点では、
- 元テーブルの不適切な cluster, partition 設定を引き継ぐことになる
- JSON 列の一部フィールドにアクセスしても、全体がパースされてしまう
といった問題が残っています。
次はこれらの問題にアプローチできる、Materialized View を見てみましょう。
Materialized View によるスキーマ定義
Materialized View は比較的新しい機能です。View と名前はついていますが、実体となるテーブル(?) を持つことで、View にアクセスするたびに再計算する必要がなくなり、高速なデータ取得が可能です。元々は集計処理の高速化のために用意された機構ですが、2021年7月から集計処理なしの Materialized View も作成できるようになりました (2021/11/16 現在はプレビュー機能)。
この Materialized View を用いることで、View のメリットを享受しつつ、さらにクエリの実行速度も向上が期待できます。
利用例
以下が Materialized View の定義例です。ほとんど View と変わらないですが、重要な変更点がいくつかあります。
create materialized view if not exists mat_view cluster by ts as select ts, cast(json_value(payload, "$.office_settlement") as BOOLEAN) as office_settlement, from base_table
もっとも、重要な差異は cluster by の追加でしょう。Materialized View は実体を持つため、元テーブルと異なる cluster 設定が可能です。元テーブルが直感に反するパーティション設定をしてしまっている際に、この機能は非常に有用です。
さらに、JSON 列のパースは実体の作成時に一度だけ行われるため、Materialized View の利用時には、アクセスするデータ量は削減され、実行速度も向上します。
この cluster 設定と JSON の事前パースにより、実際にアクセス速度向上、データ読み込み量削減の観点で大きな効果がありました。また、Materialized View は View なのでメンテナンスが不要で、元テーブルが変更された際にも自動的に追従してくれるのが大きい利点です。
JSON 読み込みの困難性と解決
ここまでは Materialized View の利点を紹介してきましたが、さまざまな制約が存在します。今回の用途で問題になった制約の一つは、UDF が利用不可能な点です。上の利用例でも JSON のパースに json_value を利用しています。
この制約によって、javascript UDF を用いた一括パースのトリックが使えなくなりました。しかし、javascript UDF の自動生成ツールと同じ仕組みを使って、以下のようなパース文は生成できるので、これ自体は大きな問題ではありません。
cast(json_value(payload, "$.office_settlement") as BOOLEAN) as office_settlement
Materialized View での、JSON のパースで問題になるのは array の処理です。以下のように、 json_value_array の返り値に対して unnest を適用すると、Materialized View ではサポートされていないとエラーが出ます。
create materialized view if not exists sample as select array( select cast(l as int64) from unnest(json_value_array(payload, "$.list")) as l ) as list, from research_oiki_json.json_sample
このような Materialized View の制約にぶつかったときの一般的な解決法は、さらに View を重ねることです。json_value_array までは、Materialized View 側で行い、cast を View で実施します。これで、事前の JSON パースによる高速化と正しい型付けの両方を享受することが出来ます。
create materialized view research_oiki_json.mat_array as select json_value_array(payload, "$.list") as list_array, from research_oiki_json.json_sample ; create or replace view research_oiki_json.mat_cover as select array( select cast(l as int64) from unnest(list_array) as l ) as list_array from research_oiki_json.mat_array
解決策はわかっているのですが、この定義文を全自動で出力するツールはまだ作れておらず、ツール作成コストが一番のデメリットですね……。
description がつけられない
これは解決できない課題なのですが、Materialized View には description がなぜかつけられません。API からもコンソールからもつけられず、どうしようもないです。
これは今後の BigQuery のアップデートに期待ですね。
エラー発生を見逃しやすい
Materialized View の実体テーブルへの書き込みは、バックグラウンドジョブで行われます。そのため、処理に失敗しても気づくのが困難です。
例えば、以下のクエリを発行した際に、JSON 列の distance フィールドに INTEGER にキャストできない文字列が含まれていたとします。実体テーブルへの書き込みはクエリ発行時に行われないため、クエリ発行時にはエラーは発生しません。
create materialized view if not exists research_oiki_json.mat_error cluster by ts select ts, cast(json_value(payload, "$.distance") as INTEGER) as distance, from `dena-auto-taxifms-data-gcp.raw_log_api.finish_deliver_v01`
しかし、裏では実体テーブルへの書き込みでこけているため、実体テーブルは作成されていません。問題は、この Materialized View へのアクセスが成功してしまうことです。以下のようなクエリは成功して、結果が返ってきます。これは、2021-11-01 のデータには不正なデータが含まれないためです。
select distance from research_oiki_json.mat_error where date(ts) = "2021-11-01"
Materialized View は「実体化していない分のデータにアクセスすると、元テーブル (との差分) へのアクセスになる」ため、Materialized View の実体化に失敗しても元テーブルへのアクセスによってクエリの実行が可能です。
これで問題になるのは、cluster 設定がされているつもりでアクセスしているのに、元テーブルにアクセスしているため、テーブルのフルスキャンになってしまう点です。エラーはまったく出現しないので、想定しないデータ利用量になっていても気づかない可能性があります。
対処法の一つは、たまに Materialized View の手動更新を実行することです。手動更新では、実体テーブルの作成に失敗するとエラーメッセージが出ます。
CALL BQ.REFRESH_MATERIALIZED_VIEW('research_oiki_json.mat_error')
Materialized View まとめ
欠点も紹介しましたが、Materialized View は View の手軽さと、テーブルの効率を両立した良いソリューションであることは間違いありません。ツールを作るコストが払えるか、対象のテーブルに array が含まれていない場合は、採用できるソリューションでしょう。
全体まとめ
ここまで、JSON 列を含んだテーブルへのアクセス方法の簡略化を検討してきました。結論として、以下の表のようなトレードオフで考えています。実運用としては、View を用いていますが、今後は Materialized View に出来るものはしたいですね。ただし、もう少し Materialized View の検証が必要な感触です。
今後の展望として、Google Cloud Next21 では JSON 型の列をサポートする予定が伝えられています。この機能の出来によっては、JSON に格納されたフィールドを通常の列と同様に扱えるようになるかもしれません。非常に楽しみな機能ですね!