
JapanTaxiの分析基盤ではワークフローエンジンにCloud Composer(Airflow)を採用しています。この記事ではどのようにワークフローを組んでいるか説明させて頂きます。
※環境はPython 3/composer-1.7.2/airflow-1.10.1です。
※この記事ではCloud Composerの基本的な概念等の説明はありません。ドキュメントを読んだ後で、どういう構成にするか検討されている方に対して数ある中の一つの解として参考になればと思います。
※BigQueryに関連する用語が出てきます。
※以後Airflowという文脈はCloud Composer(Airflow)と置き換えてください。
背景
- 分析基盤を Cloud Composer & trocco 構成に刷新しました
※背景の詳細はこちらの記事もあわせてお読みください
JapanTaxiの分析基盤の役割
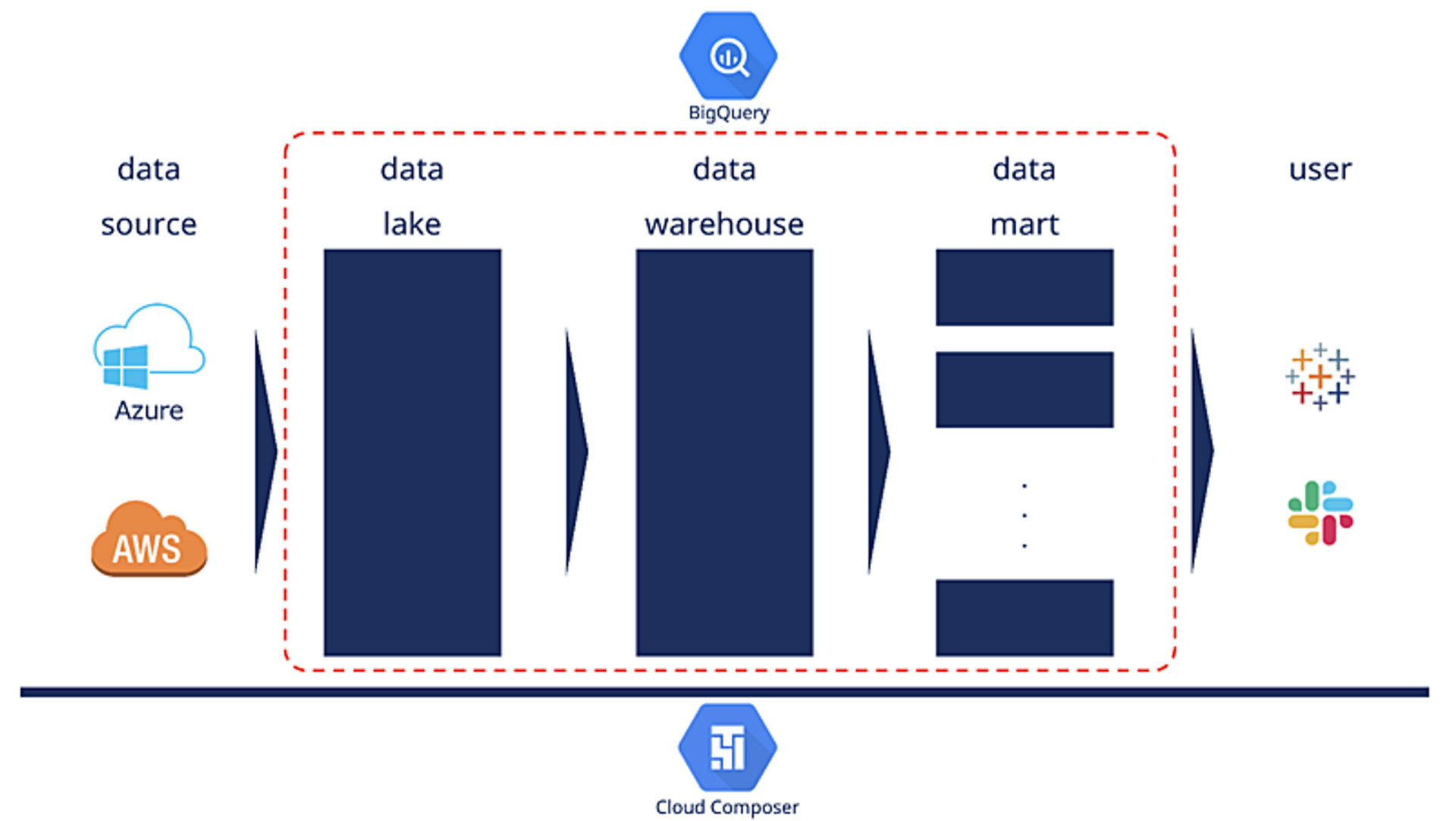
分析基盤では、AWSやAzureにあるデータをBigQueryに連携して、最終的にBIツールで可視化したり、Slackにレポートを配信することで意思決定に貢献しており、加えて、機械学習によりタクシーの到着時間予測などを予測しアプリケーションの利便性を高めています。
その中でもBigQueryはデータレイク、データウェアハウス、データマートの3つの役割を担っており、Airflowはそれらのデータを正しい順序でデータ生成するためのワークフローエンジンです。
Airflowで実装したワークフロー
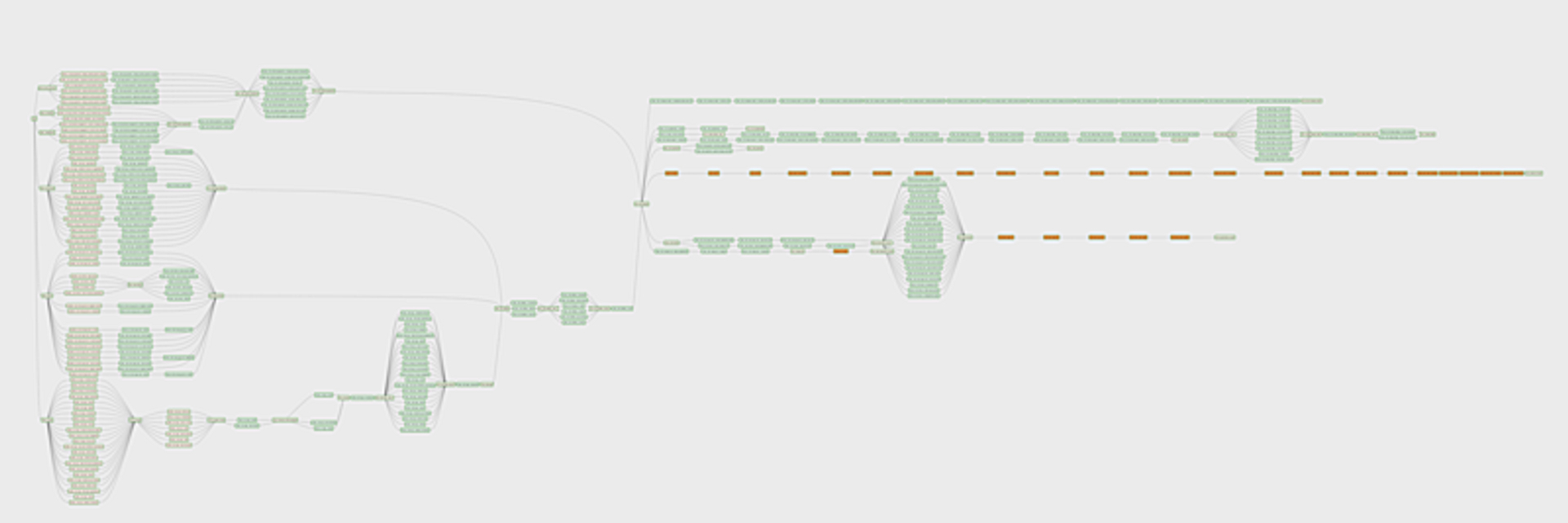
こちらが今運用している中で一番大きいDAGです。複数のプロダクトのデータソースを連携し、それらを最終的に掛け合わせる形になるため巨大なDAGを形成しています。
課題
Airflowを一通り触ってみて
Airflowの初期調査で一通り触ってみて、やりたいことはできるという確認は取れました。
そうした中で
- タスクの列挙がしんどい
- 列挙したタスクの依存関係の設定がしんどい
- データアナリストの参入障壁が高い
という課題がありました。
課題1, 2は巨大なDAGになるほどコード量が膨大になります。一つ一つのタスク設定および、それらのタスク間の依存関係の設定から実際のワークフローを想像するのは(Graphe Viewを見ればいいにしろ)大変になります。
つまり、レビューや保守が大変になることが想定され、データアナリストがワークフローを扱うのが困難になります(課題3)。
ちなみになぜデータアナリストも触れる形にしたいかと言うと、データエンジニアがすべてメンテしてもいいのですが、データアナリストもある程度参加できる環境を提供することで、分析スピードをスケールするようにしたいからです。
(僕がデータエンジニアとデータアナリストを兼任しているからという理由もあります)
解決策
自作フレームワークの導入
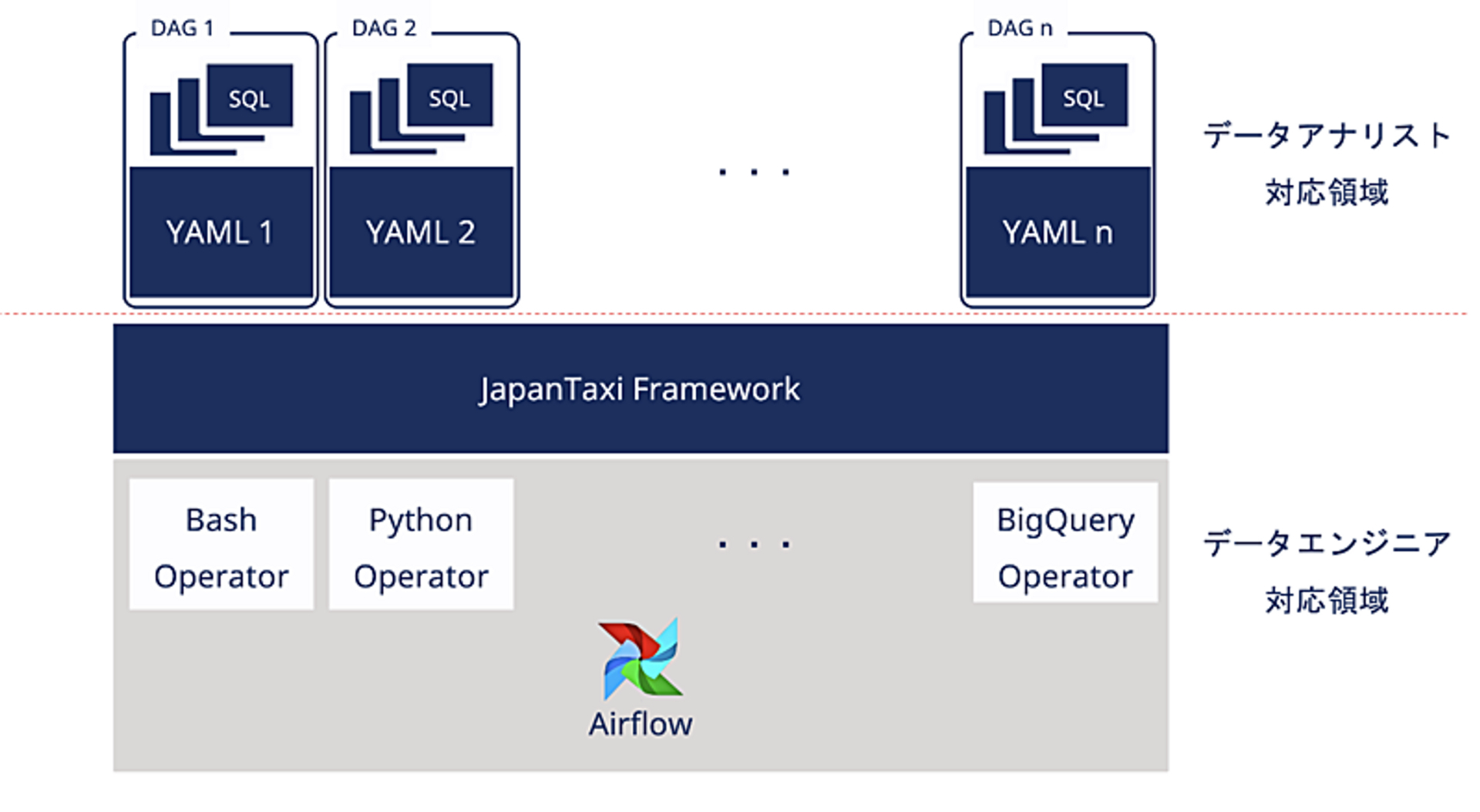
解決策として、自作のフレームワーク(JapanTaxi Framework)を導入しました。
基本的にはデータエンジニアが一度完全に動く形でワークフローを作成します。その後の仕様変更はデータアナリストでもメンテ可能な形に分離しました。この構成により、根幹の部分であるDAGを触ることなく、YAMLの編集だけでタスクを追加することができるようになります。
基本的なアイデア
どういった機能があれば課題を解決できるか。基本的なアイデアは下記のとおりです。
- あるパラメータをフレームワークに渡すと、パラメータに準じたオペレーターを呼び出してタスクを生成する
- 生成されたタスクから一定のルールでタスク間の依存関係を設定する
- タスク生成に必要なパラメータをDAGからYAMLに分離してデータアナリストでも扱いやすくする
これらについて一つずつ説明したいと思います。
オペレータ生成器の導入(課題1「タスクの列挙がしんどい」への対応)
まず、タスクの列挙は辞書型で管理するようにしました。この辞書をフレームワークに渡すと、記述されたパラメータに準じたオペレータを呼び出し、タスクを生成します。例えば
- データソースからBigQueryにデータ連携させるタスク
- BigQueryにSQLを実行させるタスク
- レポートを配信させるタスク
のような形です。例えば、BigQueryを指定した場合、通常引数として使うパラメータは下記の通りです。
BigQueryOperator( task_id=#タスクID, write_disposition=#出力先テーブルの書き込み時の挙動, create_disposition=#出力先テーブルが存在しない時の挙動, allow_large_results=#巨大な結果を許すか, bql=#実行するSQL文字列, use_legacy_sql=#レガシーSQL/スタンダードSQL, destination_dataset_table=#出力先プロジェクト名.データセットID.テーブル名, time_partitioning=#タイムパーティション )
オペレータ生成器ではBigQueryOperatorをラッピングすることで
の指定で済むようにしています。これらの引数をもとにSQLファイルを別途読み込み、かつ指定しない引数はデフォルト値がセットされます。
※デフォルト値以外を指定したい時だけパラメータを設定する。
※SQLファイルは「plugins/queries/dataset_id/table_name.sql」というパスをデフォルトにして読み込むようにしています。
また、最終的にBigQueryOperatorに設定する
- destination_dataset_table
- write_disposition
についてはパラメータの設定ミスを追えるように別途ログに出すようにしています。
ブロックの導入(課題2「列挙したタスクの依存関係の設定がしんどい」への対応)
Airflowでは、タスクとタスクの実行順序を紐付ける書き方はいくつかあります。どのような書き方をするにしろ、タスクの数が多くなるほどコードが見づらくなります。
そこで、一定のルールに則った紐付けをフレームワークにさせればコードを簡素にできると考えました。
一定のルールとは、ワークフローは基本的には直列にタスクを実行するか、並列にタスクを実行するかなので、このルールをフレームワークで実現しました。
直列
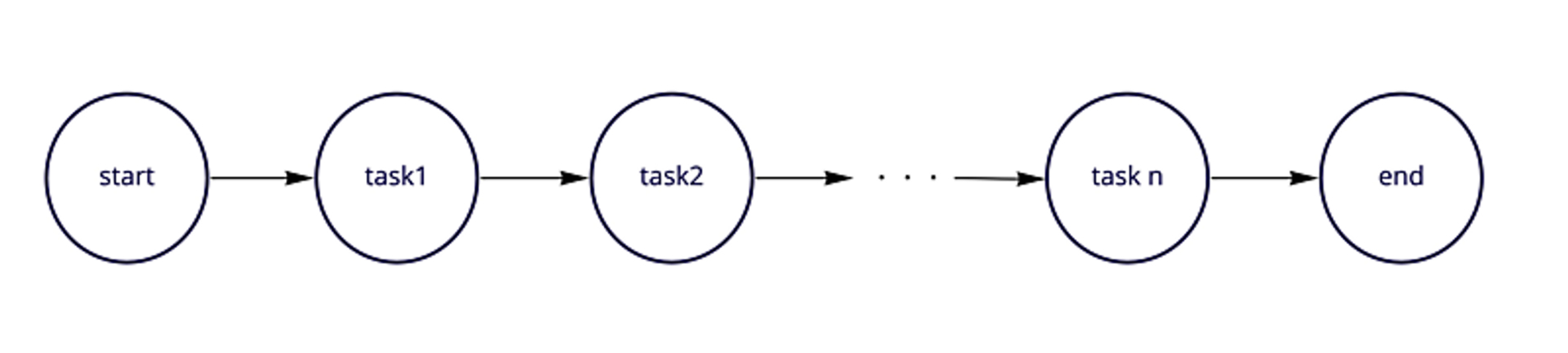
実行したいタスクがn個あったとき、このように直列で実行したい場合があります。
並列
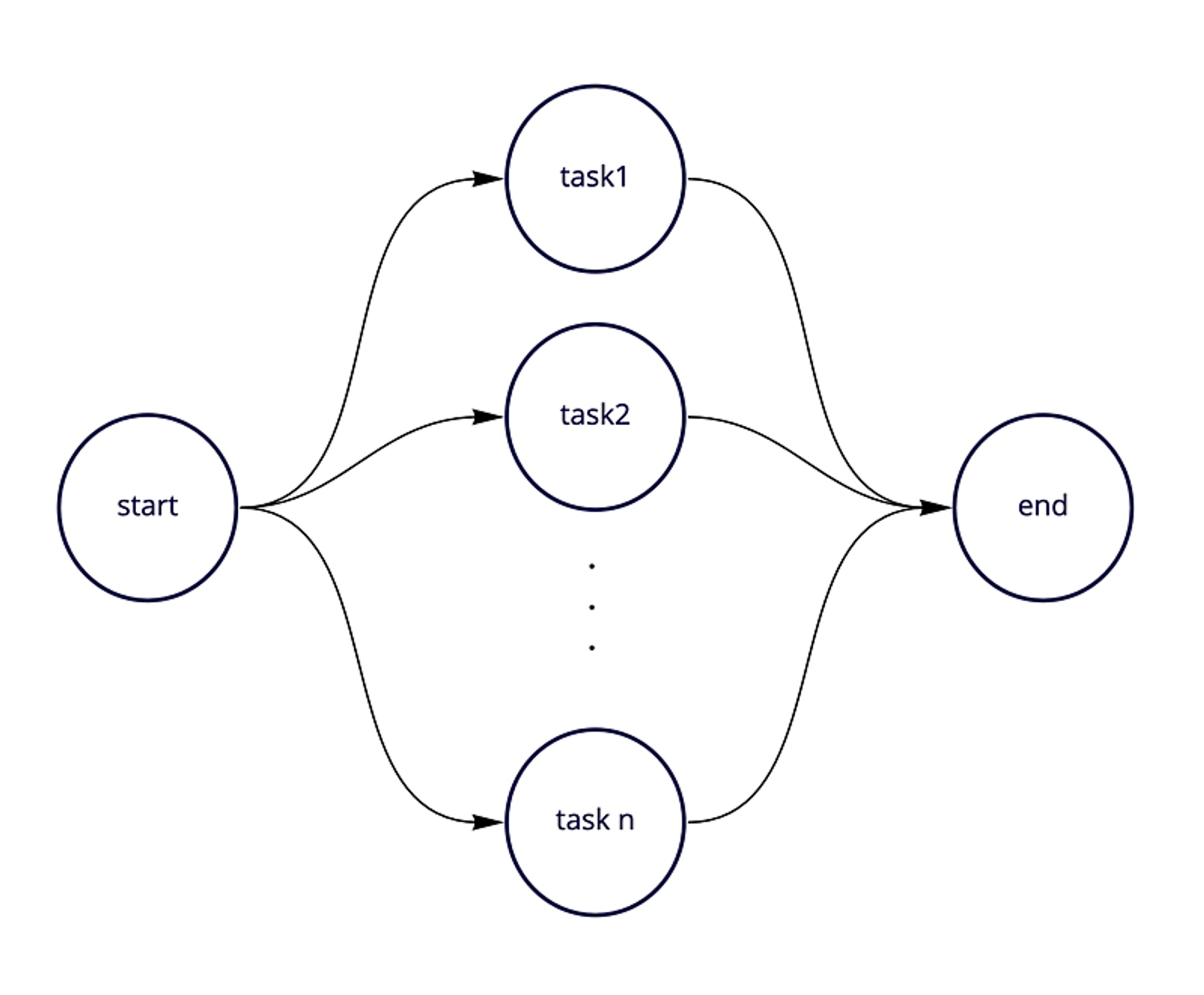
実行したいタスクがn個あったとき、このように並列で実行したい場合があります。
※startとendはダミータスクです
n個のタスクをフレームワークに渡すと、ダミーとなるstartとendを自動的に生成し、startからendの間に実際に実行したいタスクを直列/並列で紐付けるようにしました。
このstartからendまでの塊を僕らはブロックと呼んでおり、直列ブロック/並列ブロックをフレームワークに生成させ、これらのブロックを組み合わることでDAGを形成します。
例として、データレイク層で実行したいブロック、データウェアハウス層で実行したいブロック、データマート層で実行したいブロック、レポート配信で実行したいブロックを生成し、組み合わせることになります。
ブロックにすると何が嬉しいのか
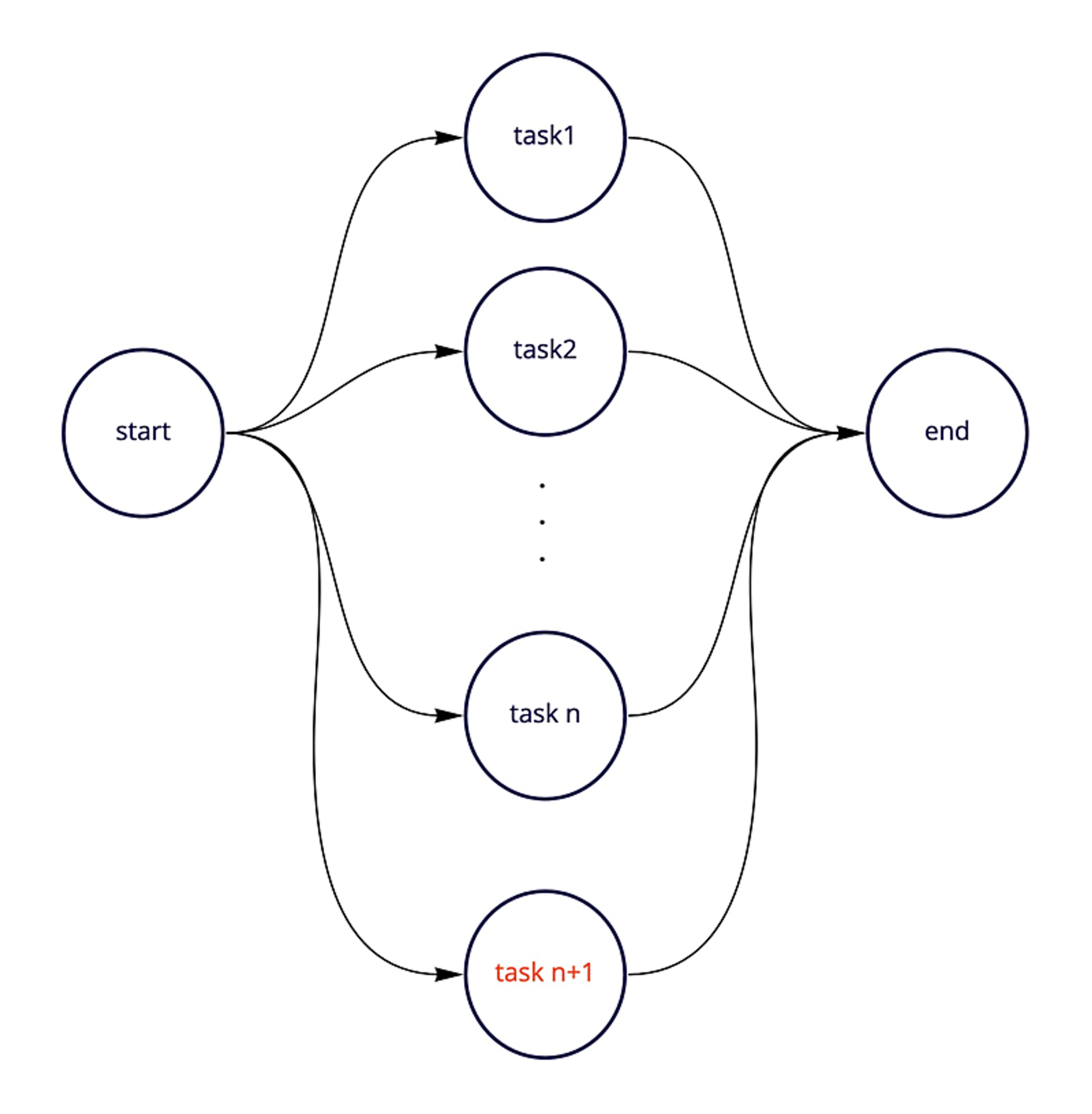
連携するデータを追加するとき、並列で1個タスクが増えることはプロダクトが成長している以上よくあることです。

同様に仕様変更により直列で1個タスクが増えることは新しい分析要求がある以上よくあることです。このようにタスクを一つ追加したときに、ブロック機能によりタスクの依存関係も自動的に設定されることになり、いちいち依存関係の設定をせずに済みます。
YAMLによるDAGとの分離(課題3「データアナリストの参入障壁が高い」への対応)
今までDAG内に持っていたタスクの情報をDAGから分離し、YAMLで管理するようにしました。
YAMLのデータレイク層やデータウェアハウス層へのデータ連携定義はデータエンジニアが設定し、データマート層の定義だけをデータアナリストに触らせることによって変更できる範囲を絞り込み、データアナリストの参入障壁を下げています。
百聞は一見に如かずということで、YAMLに記述する例を挙げさせて頂きます。データアナリストはこのようなYAMLを書くだけでワークフローに処理を追加できます。
- block_name: 'datawarehouse' run_type: 'parallel' # parallel(並列)/serial(直列) dataset_id: 'dataset_datawarehouse' # 出力先データセットID op_list: #Operatorリスト - type: 'bq' # bq(BigQuery)/tc(trocco※データ連携)/pm(レポート配信) table_name: 'table1' # 出力先テーブル名 table_name_partition_type: 'yesterday' # 出力先日付パーティション time_partitioning: # パーティションフィールド field: 'timestamp' type_: 'DAY' - type: 'bq' table_name: 'table2' write_disposition: 'WRITE_APPEND' # デフォルトWRITE_TRUNCATE(洗い替え) - block_name: 'datamart' run_type: 'serial' dataset_id: 'dataset_datamart' op_list: # 以下略
まとめ
今回、導入したフレームワークは
- 指定されたYAML内のキーを読み込む機能
- 読み込んだパラメータに準じたオペレータを呼び出し、タスクを生成する機能
- 生成したタスクを一定のルールで依存関係を設定するブロック機能
を持っています。
これらの機能を持つことで
- タスクの列挙がしんどい
- 列挙したタスクの依存関係の設定がしんどい
- データアナリストの参入障壁が高い
という3つの課題を解決しました。
このフレームワークの導入によって開発の生産性を向上させ、かつデータアナリストも参加できる環境を提供することができました。これにより、データエンジニアとデータアナリストの作業分担を可能とし、分析スピードをスケールさせることができます。
運用の観点では、DAGがワークフローの根幹である以上、本番リリース後はDAGはあまり触りたくないというのが実情です。部品であるYAMLやSQLファイルの変更をレビューするほうがとても楽なのです。
また、保守の観点では、フレームワークを通してYAMLを読み込んでブロックを生成し、ブロックを組み合わせることでワークフローを構成するというお作法に統一されることで保守性がある程度担保されることになります。
このようにして本番運用を意識したAirflowの実装を実現しました。
おわりに
以上でJapanTaxiにおけるCloud Composer(Airflow)の付き合い方を説明させて頂きました。今後はCloud Composerによるワークフローの適用範囲をさらに広げて、より付加価値の高い分析基盤を構築していきたいと思っています。