※本記事の背景にある「道路情報の差分抽出プロジェクト」は、2025年8月1日付けで会社分割に伴い新会社GOドライブ株式会社に移管されました。現在は、GOドライブ社のテックブログにて継続的に技術情報を発信していますので、そちらもご参照ください。
こんにちは、AI技術開発部AI研究開発第二グループの劉です。私は、道路情報の自動差分抽出プロジェクトにて、ドラレコ映像から標識などの物体を見つける機能の開発を担当しており、その中で画像の分類が必要になります。現在、最先端の画像分類モデルの1つとしてConvNeXtがありますが、アーキテクチャがImageNetの224x224という画像サイズに合わせて設計されおり、例えば32x32といったより小さいサイズの画像を扱う私たちのタスクでは性能を出しきれないという課題がありました。本記事では、小さい画像に対して良好な性能が得られるように、ConvNeXtのアーキテクチャを変更していく流れとその結果をご紹介したいと思います。
はじめに
本記事では、以下の論文を取り上げます。コンピュータビジョンで最も有名な国際学会の一つであるCVPR2022に採択された論文です。
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie. “A ConvNet for the 2020s”, CVPR 2022. [PDF] [Github]
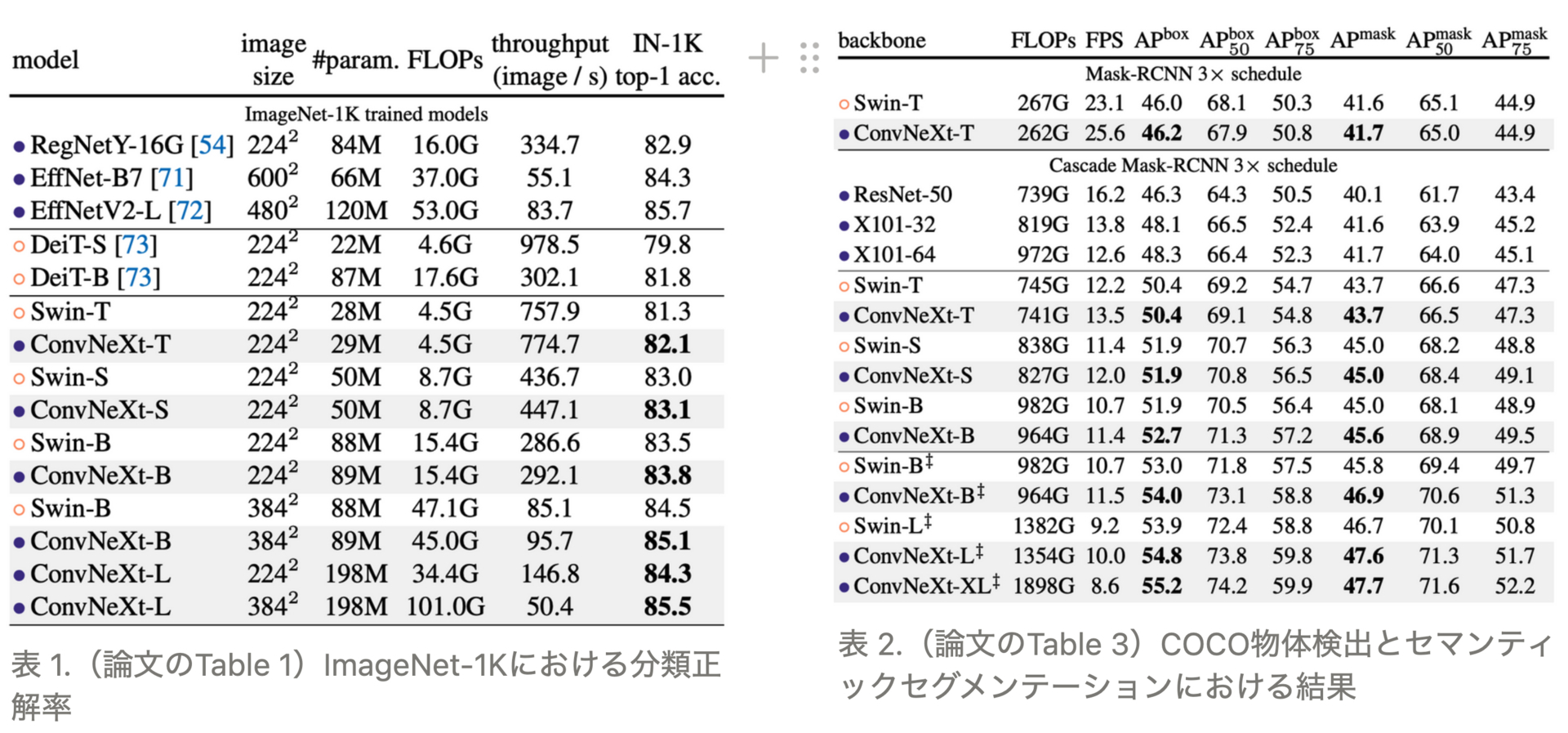
コンピュータビジョンにおいては長らくCNNがデファクトスタンダードでしたが、最近ではTransformerが大きな躍進を見せ、例えばSwin-Transformerは画像分類や物体検出において多くのCNNモデルを上回る精度を達成しました。これに対し本論文では、CNNにはまだ改善の余地があり、アーキテクチャを見直すことでSwin-Transformer以上の精度が得られることを示しています(表1、表2)
早速私たちもConvNeXtを利用してみたいと思ったのですが、私たちのタスクではドラレコ映像からクロップした標識の画像を分類モデルへ入力する場合があり、このときの画像サイズは32x32ピクセル程度とかなり小さくなります。そこで画像サイズ32x32のデータセットの代表例であるCIFAR10でResNet50とConvNeXtの分類精度を比較したところ、ResNet50が勝ってしまいました(詳細は後述しますが、ResNet50が96.74%なのに対し、ConvNeXtは89.8%)。これは、ConvNeXtがImageNetでの評価を前提として224x224ピクセルの入力画像を想定して開発されたためであり、より小さなサイズの画像に対してConvNeXtの性能を引き出すためには何らかのチューニングが必要と考えられます。本記事では、その一例として私たちが実施したConvNeXtのアーキテクチャ調整についてご紹介します。
ConvNeXtの概要
ConvNeXtはResNetをベースとしていて、図1のような変更が加わっています。ImageNetにおいて、ConvNeXt-Tの正解率が82.00%で、ResNet50の78.8%より大幅に改善されており、同等計算量のSwin-Tの81.30%よりも正解率が高いです。
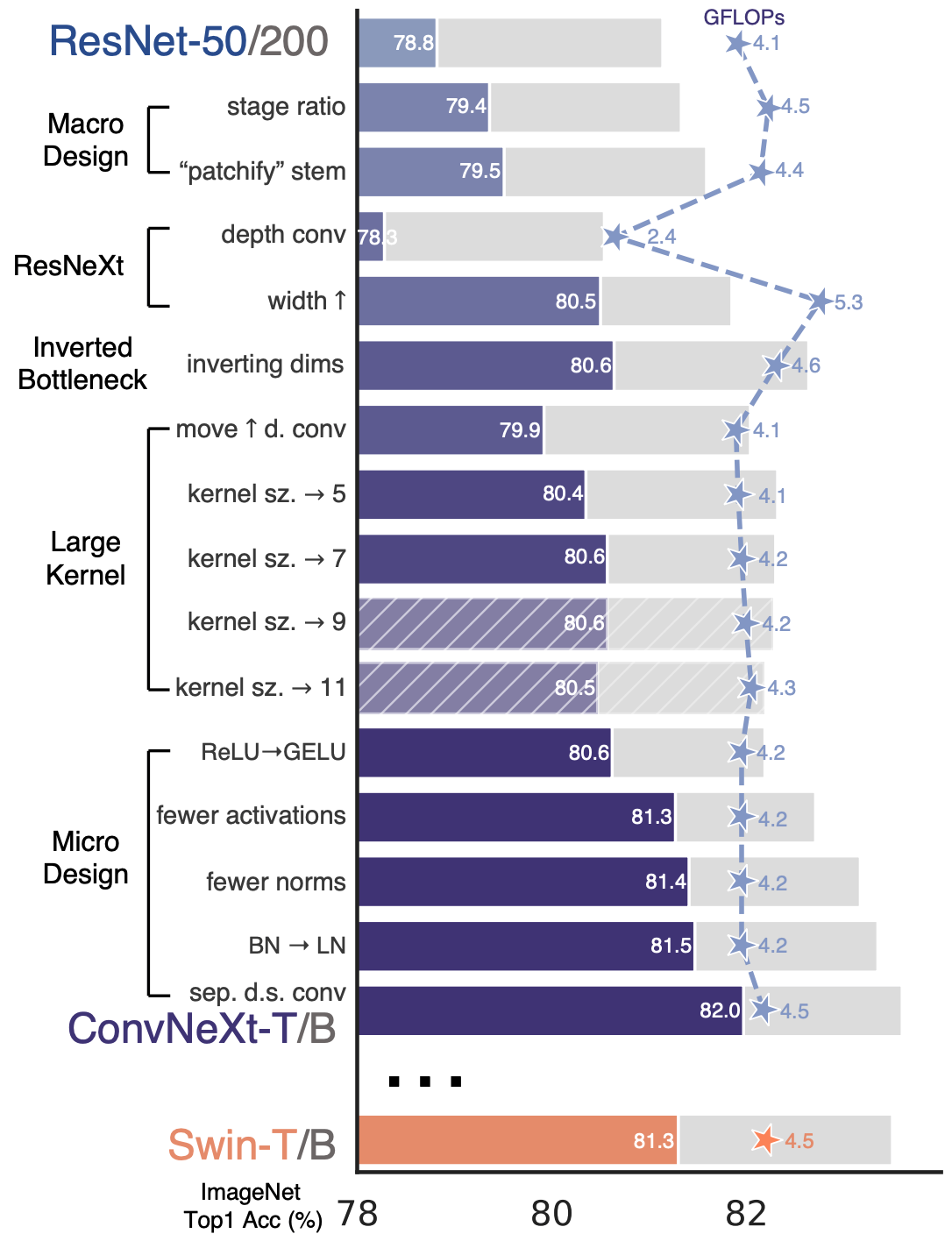
図 1. (論文のFigure 2)スタンダードの ConvNet(ResNet)からConvNeXtに変更する流れ
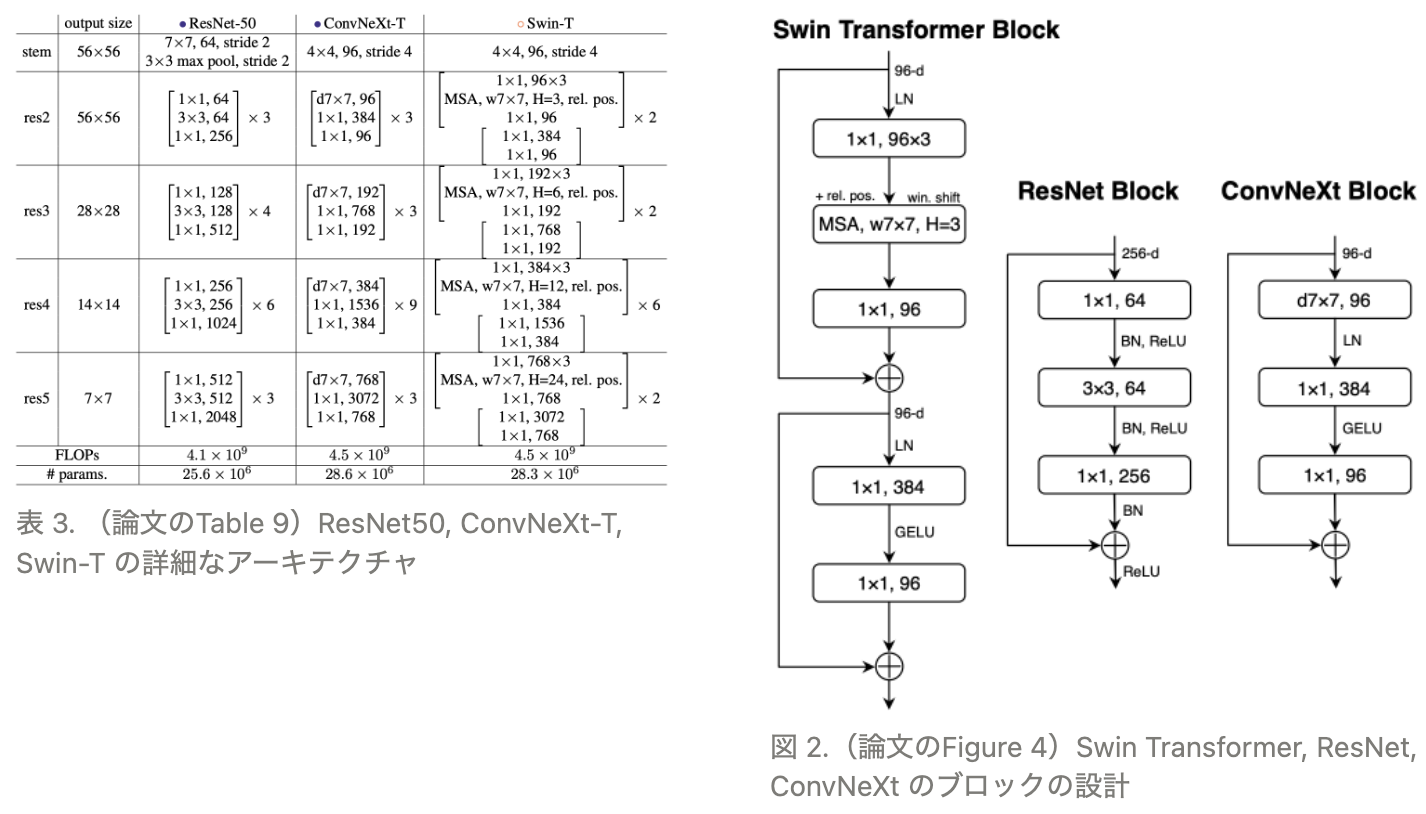
表3に示すように、ResNet50のstage ratioの res2:res3:res4:res5 = 3:4:6:3 に対し、ConvNeXt-Tは、Swin-Tと同じように res2:res3:res4:res5 = 1:1:3:1 に変更し、ConvNeXtのstemもSwin-Tと同じに変更しています。また、図2に示すように、ConvNeXtのBlockは、ResNet50と比べて、通常のConvをdepth Convに、Batch NormalizationをLayer Normalizationに、活性化の回数を減らしてReLUをGELUに変更しています。
アーキテクチャ改善の流れ
Baseline
図1にも示したようにConvNeXtの論文ではResNet50からConvNeXt-Tへとアーキテクチャを変更しているため、ここでもResNet50の精度を比較対象とします。ResNet50のアーキテクチャは、ResNetの提案論文中の「4.2. CIFAR-10 and Analysis」に記載されている、CIFAR10に最適化したもの(Conv1のkernel_size=3x3, Conv1後ダウンサンプリングなし)を使用します。データ拡張はConvNeXtのデフォルトと同じものを採用します。一方ConvNeXtのハイパーパラメータは、バッチサイズを128、学習epoch数を200に変更した以外はデフォルトのままです。
CIFAR10での分類正解率をResNet50とConvNeXtで比較した結果を表4に示します。デフォルトのConvNeXt-TはCIFAR10に最適化されたResNet50よりも約7ポイント正解率が低い結果となりました。これをベースラインとして、CIFAR10における分類正解率を高めるようにConvNeXtのアーキテクチャを変更していきます。
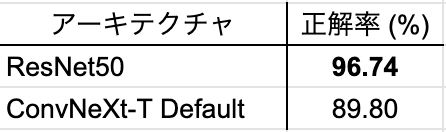
表 4. ResNet50とConvNeXt-T Defualt実装の結果
Step1. stemの変更
変更前:
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
変更後:
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=3, stride=1, padding=1),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
ConvNeXtのstemにおけるConv2dではstride = 4となっており、入力画像が32x32の場合、特徴マップのサイズが一気に8x8になってしまいます。そこで、stemではサイズを変更せず、stem以降で32 → 16 → 8 → 4とサイズを小さくしていくように変更しました(kernel_size = 3, stride = 1, padding = 1)。これにより、表5に示した通り、CIFAR10における分類正解率は89.8%から96.85%と大きく改善し、ResNet50の正解率を若干上回りました。
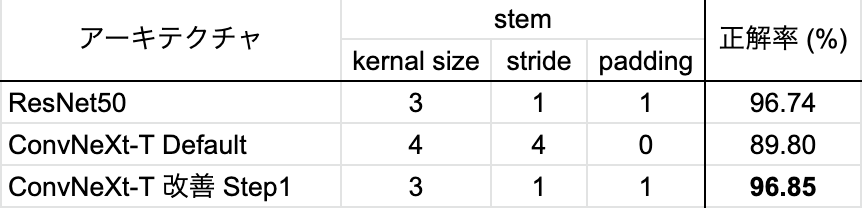
表 5. stem部分の変更による改善の結果
Step2. blockの変更
変更前: self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv 変更後: self.dwconv = nn.Conv2d(dim, dim, kernel_size=3, padding=1, groups=dim) # depthwise conv
図1に示した通り、ConvNeXtのblockではカーネルサイズを大きくして7にしていますが、入力画像サイズが小さい場合はやはりカーネルサイズも小さくすべきと考えられます。そこでカーネルサイズ3と5の場合を比較しました。表6に示した通り、両方とも正解率が同等になり、計算量の少ない「kernel_size = 3, stride = 1, padding = 1」を採用します。
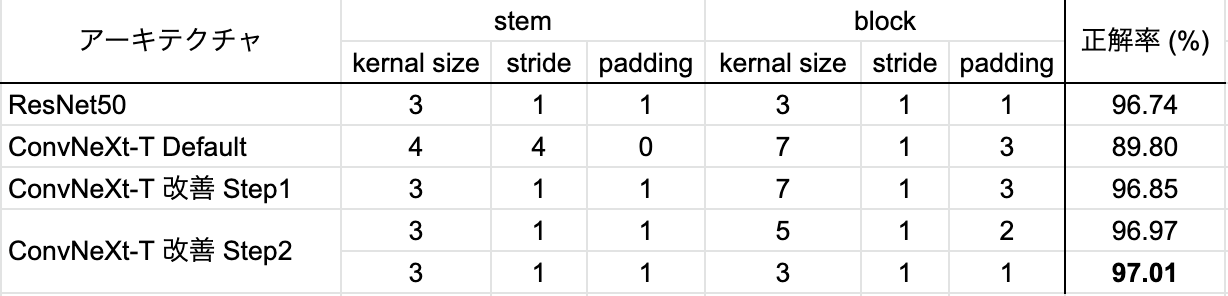
表 6. block部分の変更による改善の結果
Step3. downsamplingの変更
変更前:
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
変更後:
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=5, stride=2, padding=2),
)
downsamplingにおけるカーネルサイズも調整してみました。結果は表 7の通りで、「kernel_size = 5, stride = 2, padding = 2」のほうがより高い正解率が得られました。
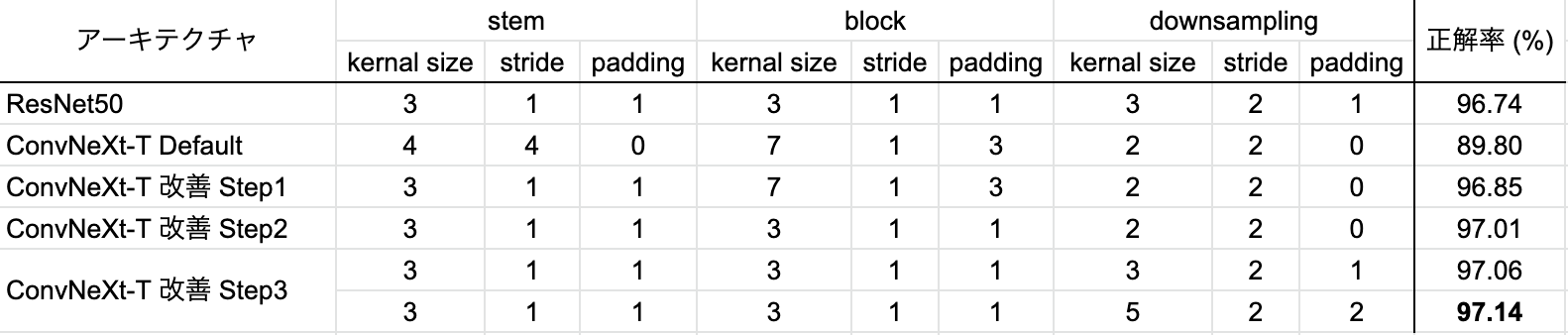
表 7. downsampling部分の変更による改善の結果
おまけ. 統計量の変更
変更前: mean = IMAGENET_INCEPTION_MEAN if not imagenet_default_mean_and_std else IMAGENET_DEFAULT_MEAN std = IMAGENET_INCEPTION_STD if not imagenet_default_mean_and_std else IMAGENET_DEFAULT_STD 変更後: mean = [0.5071, 0.4867, 0.4408] std = [0.2675, 0.2565, 0.2761]
入力の前処理において、ConvNeXtのデフォルトは、ImageNetの統計量を使っています。画像サイズとは関係ない話であり、また当たり前のことではあるものの、サボりがちなためおまけとして記載しておきますが、ちゃんとCIFAR10の統計量で正規化してあげると表8のように若干精度が改善しました。

表 8. 入力正規化の統計量の変更による改善の結果
最高速度制限標識の分類に適用した結果
さて、読者の方々のイメージがつきやすいようここまでCIFAR10での精度比較を実施してきましたが、実際に私たちが業務で行っている画像分類ではどのような結果となったかもご紹介したいと思います。一例として、図3のように、ドラレコ映像から検出した速度標識を通常型、LED型(点灯)、LED型(消灯)の3つに分類するタスクでResNet50とConvNeXtを比較した結果を表9に示します。この表から分かるように、CIFAR10と同様、私たちのタスクにおいてもこれまで説明してきたConvNeXtのアーキテクチャ調整が効果を発揮していることが分かります。

図3. 通常型、LED型(点灯)、LED型(消灯)
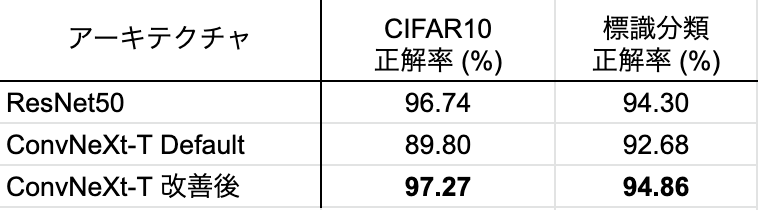
表 9. 私たちの標識分類に適用した結果とCIFAR10の結果のまとめ
まとめ
本記事では、画像分類におけるSoTAモデルの一つであるConvNeXtに着目し、自分たちのプロジェクトで扱う小さなサイズの画像に対してその性能を引き出すためのアーキテクチャ調整についてご紹介しました。論文等で提案された最新技術を自分たちのタスクに適用する場合は、単にそのまま使うのではなく、細部を理解して適切に調整・改良してタスクにフィットさせることが重要です。今後も私たちは、最先端のCV技術を活用・創造し、自分たちのサービスで社会課題を解決することを目指していきます。