SREグループの古越です。
MoTのサービスは多くがAWSのAurora MySQLまたはPostgreSQLを利用しリーダーエンドポイントを利用し参照クエリを発行しています。一部のサービスはGoogle Cloud上で構成されており、Cloud SQLの参照クエリの負荷分散が課題としてありました。
EKSからCloud SQLに対する負荷分散アプローチを検討する機会があり検証したところ、HAProxyサイドカーとして横付けする方法が有用と分かりましたので本記事で紹介いたします。
はじめに
本記事執筆時点では実験的な内容となります。近日中にプロダクションに投入予定ですので、何かトラブルがあれば別途共有できればと思います。
構成イメージ
本記事で紹介する構成のイメージ図です。
前提として、EKSなどのGoogle Cloud以外のKubernetesクラスターから接続するケースを想定しています。
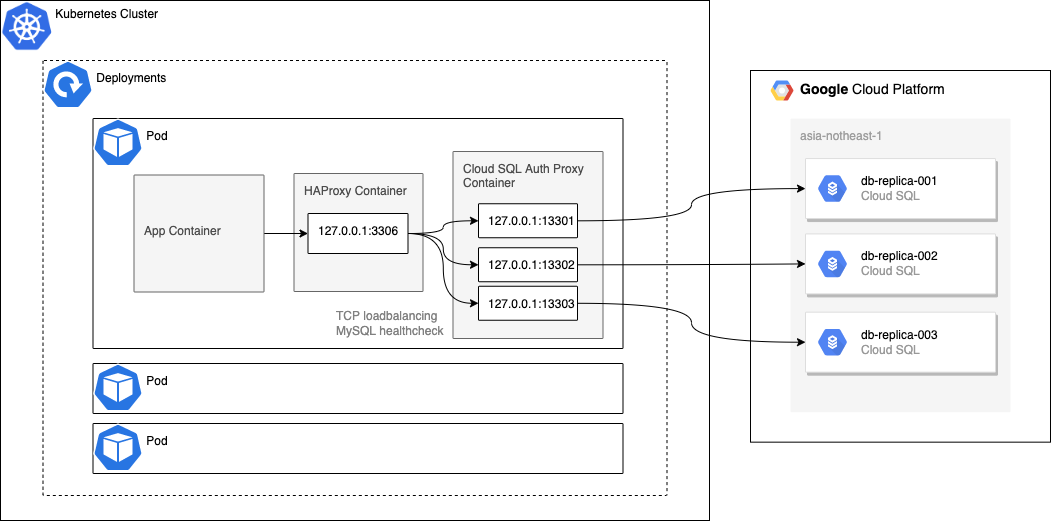
Kubernetes上で構成したアプリケーションからCloud SQL Replicaへの経路のみ抜粋します。
アプリケーションの通信流入経路やCloud SQLのMaster接続経路については割愛します。
構成要素について
簡単に構成要素について解説します。
Cloud SQL
https://cloud.google.com/sql/docs/introduction?hl=ja
Google CloudマネージドのMySQLサービスです。
マネージドMySQLとしてはAmazon RDSが比較対象になりますが、RDSの場合は選択肢としてAurora MySQLが有ります。Aurora MySQLを基準に考えると機能が幾つか不足しています。

管理面に課題が多いのですが、Google CloudのマネージドMySQLは選択肢が少ないため、仕方なくCloud SQLを選択するケースが多いかと思います。負荷分散出来る参照用エンドポイントが無い事が今回の構成を作る動機となっています。
Google CloudのマネージドDBとしてAuroraに対抗する形で2022年5月にAlloyDB for PostgreSQLがリリースされていますが、今後MySQL版が出て不足部分が解消される事を期待しています。
Cloud SQL Auth Proxy (Cloud SQL Proxy)
https://cloud.google.com/sql/docs/mysql/sql-proxy?hl=ja
コンテナで起動し、Cloud SQLに接続可能にするための認証プロキシです。Google Cloudサービスアカウントさえ有れば、Google Cloudの外部からCloud SQLに接続可能になります。
ポイント
- ネットワーク上の境界を無視しつつも、セキュアな接続を実現する
- k8s上で使う場合、サイドカー方式で横付けする方法が公式で推奨されている
- 1コンテナで複数Replicaに対する接続ポイントを作る事が出来る
- distrolessを使ったコンテナイメージがデフォルト提供 10MB未満に収まる
- 認証プロキシに過ぎないため、複数レプリカに対して負荷分散する機能は持たない
HAProxy
初版リリース 2001/12/16 の古くから存在するOSSのTCPロードバランサです。
ポイント
- Cで実装され、高い信頼性があり、高速で、多数の実績がある
- 古くから有り成熟している
- コンテナ化されている
- イメージはDockerHubで提供
- alpine版のコンテナイメージは10MB未満と軽量
2015年頃まではMySQL参照クエリの負荷分散アプローチとしてはReplica(MySQL Slave)を作成し、HAProxyなどのTCPロードバランサを利用して分散するアプローチが比較的有名でした。
2016年頃にAurora リーダーエンドポイントが登場した後はAuroraがマネージドMySQLとして決定的な地位を確立したことも有り、MySQL負荷分散としてHAProxyを活用する事例を殆ど見なくなりました。
今回Cloud SQLの負荷分散アプローチとして使えるか改めて調査した所、コンテナ化したアプリケーション上でも使える事が分かりました。
HAProxy導入動機
動機は負荷分散装置を入れて以下のメリットを得るためです。
HAProxyを採用した決め手
HAProxy以外にも負荷分散装置としてはProxySQLやEnvoyを検討していました。
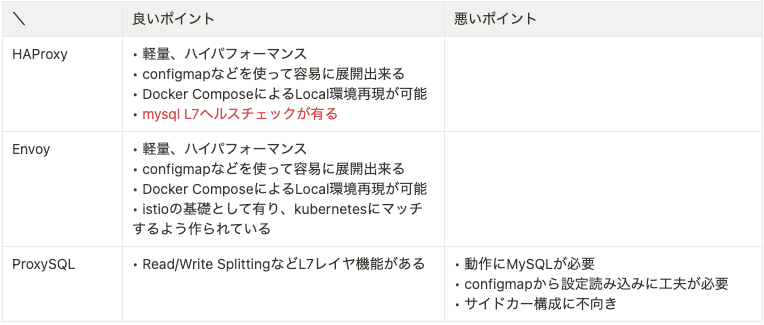
当初ProxySQLが使えると考えていたのですが、小規模かつサイドカー構成するという前提にマッチしなかったため候補から外す事になりました。シンプルなTCPロードバランサで事が足りるためEnvoyも良さそうでしたが、L7ヘルスチェックの有無が決め手で今回はHAProxyを採用しています。
ロードバランサからのヘルスチェックについて
今回想定していたサービスではGoogle Cloud外部から接続するため、Cloud SQL Auth Proxyの利用が必須でした。
App → [loadbalancer] → Cloud SQL Auth Proxy →Cloud SQL
という多段の接続経路になります。
この多段経路の場合、ロードバランサからのTCPヘルスチェックだけではCloud SQL Auth Proxyの裏に有るCloud SQL障害を十分に検知出来ないと想定しています。
構成方法
- Docker Composeを使い、localマシンからCloud SQLへ接続する方法
- KubernetesクラスターからCloud SQLに接続する方法
の2パターンを紹介いたします。
準備
以下は既に準備出来ている前提で記載します。
今回は詳しく触れませんが、実際にお試し頂く場合は別途準備いただければと思います。
共通: HAProxy ヘルスチェックユーザの準備
準備として、HAProxyからMySQLに対するヘルスチェックを行うユーザを作成します。
今回はDocker Compose, Kubernetes共用のヘルスチェックユーザの例を記載します。
ユーザ作成コマンド
CREATE USER 'healthcheck'@'cloudsqlproxy~%' WITH MAX_QUERIES_PER_HOUR 1 MAX_UPDATES_PER_HOUR 0;
ヘルスチェックユーザからはクエリを発行する必要が無いため、GRANTなどの設定は不要です。念の為、 MAX_QUERIES_PER_HOUR, MAX_UPDATES_PER_HOURなどのパラメータでクエリ発行出来ないよう絞っておくと良いかも知れません。
ヘルスチェックユーザについての細かい説明はHAProxyのドキュメントが参考になります。
参考: https://www.haproxy.com/documentation/hapee/latest/onepage/#4.2-option%20mysql-check
Docker Compose版
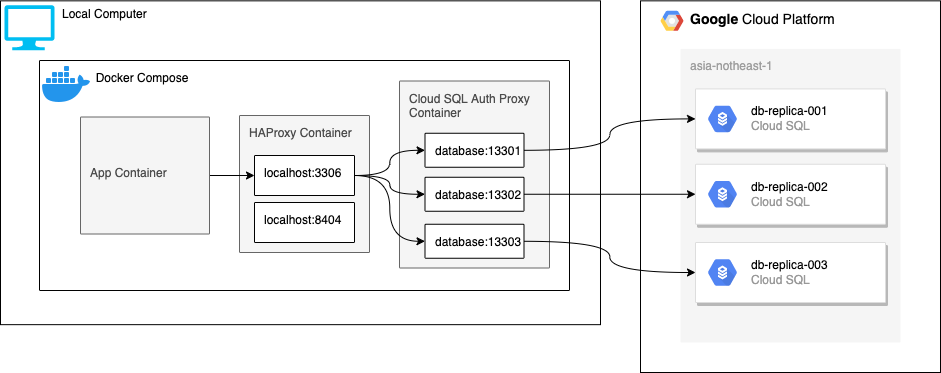
開発用マシンと開発用のCloud SQL Replicaが存在する前提になりますが、Kubernetesに乗せる前の確認として利用出来るので紹介いたします。
アプリケーションコンテナの内容は割愛しますが、アプリケーションから localhost:3306 として参照出来るようになります。
docker-compose.yml 例
version: '3' services: # ---------- # CloudSQLAuthProxy # ---------- database: image: "gcr.io/cloudsql-docker/gce-proxy:1.30.0" environment: - GOOGLE_APPLICATION_CREDENTIALS=/var/run/secret/cloud.google.com/service-account-key.json command: ["/cloud_sql_proxy", "-instances=your-project:asia-northeast1:db-replica-001=tcp:0.0.0.0:13301,your-project:asia-northeast1:db-replica-002=tcp:0.0.0.0:13302,your-project:asia-northeast1:db-replica-003=tcp:0.0.0.0:13303"] volumes: - "./secrets:/var/run/secret/cloud.google.com" ports: - "13301-13303:13301-13303" # ---------- # HAProxy # ---------- haproxy: image: "haproxy:2.5-alpine" ports: - "8404:8404" - "3306:3306" volumes: - "./haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg"
Cloud SQL Auth Proxyのサービスアカウントキー
docker-compose.ymlファイルの相対pathとして 以下に配置する想定です。
./secrets/service-account-key.json
複数レプリカの登録
cloud_sql_proxy の -instances 引数にCloud SQLインスタンスを書きますが、カンマ区切りで繋げて書くと複数個のCloudSQL Replicaを登録する事が出来ます。
登録したレプリカの数だけ待受ポートが作られるのでHAProxyで繋げていきます。
haproxy.cfg 例
global
log stdout format raw local0
defaults
log global
retries 3
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
maxconn 3000
listen mysql
bind *:3306
mode tcp
option mysql-check user healthcheck
balance roundrobin
server replica-001 database:13301 check port 13301
server replica-002 database:13302 check port 13302
server replica-003 database:13303 check port 13303
listen stats
bind *:8404
mode http
maxconn 10
timeout queue 100s
stats enable
stats refresh 30s
stats show-node
stats uri /stats
コンテナ間通信の補足
docker-composeの場合、コンテナ間通信に少し注意が必要でdocker-composeの名前解決に委ねる形が好ましいです。
上記の Pdatabase:13301 と記載されている所は、HAProxy → Cloud SQL Auth Proxyの通信部分になります。Kubernetesの場合は loopback IPで 127.0.0.1:13301 と記載しますが、docker-composeの名前解決を利用するため docker-compose.ymlに記載したservice名 database を指定して設定しています。
stats 閲覧
docker-compose版は開発や動作確認を目的としているので、ヘルスチェックの挙動確認するためにstatsを有効化しています。
docker-compose起動後にブラウザで http://localhost:8404/stats を開くと以下の統計情報を見ることが出来ます。
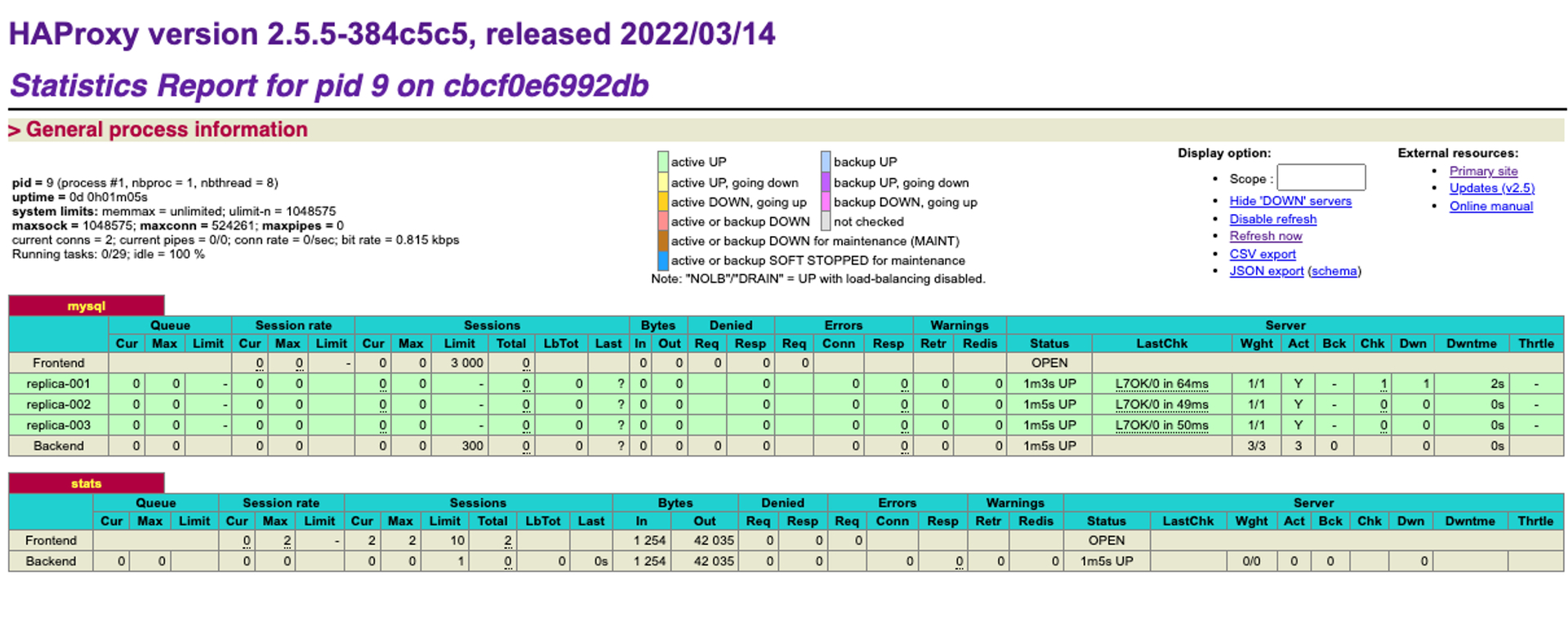
Docker Compose版の紹介としては以上です。
Kubernetes版
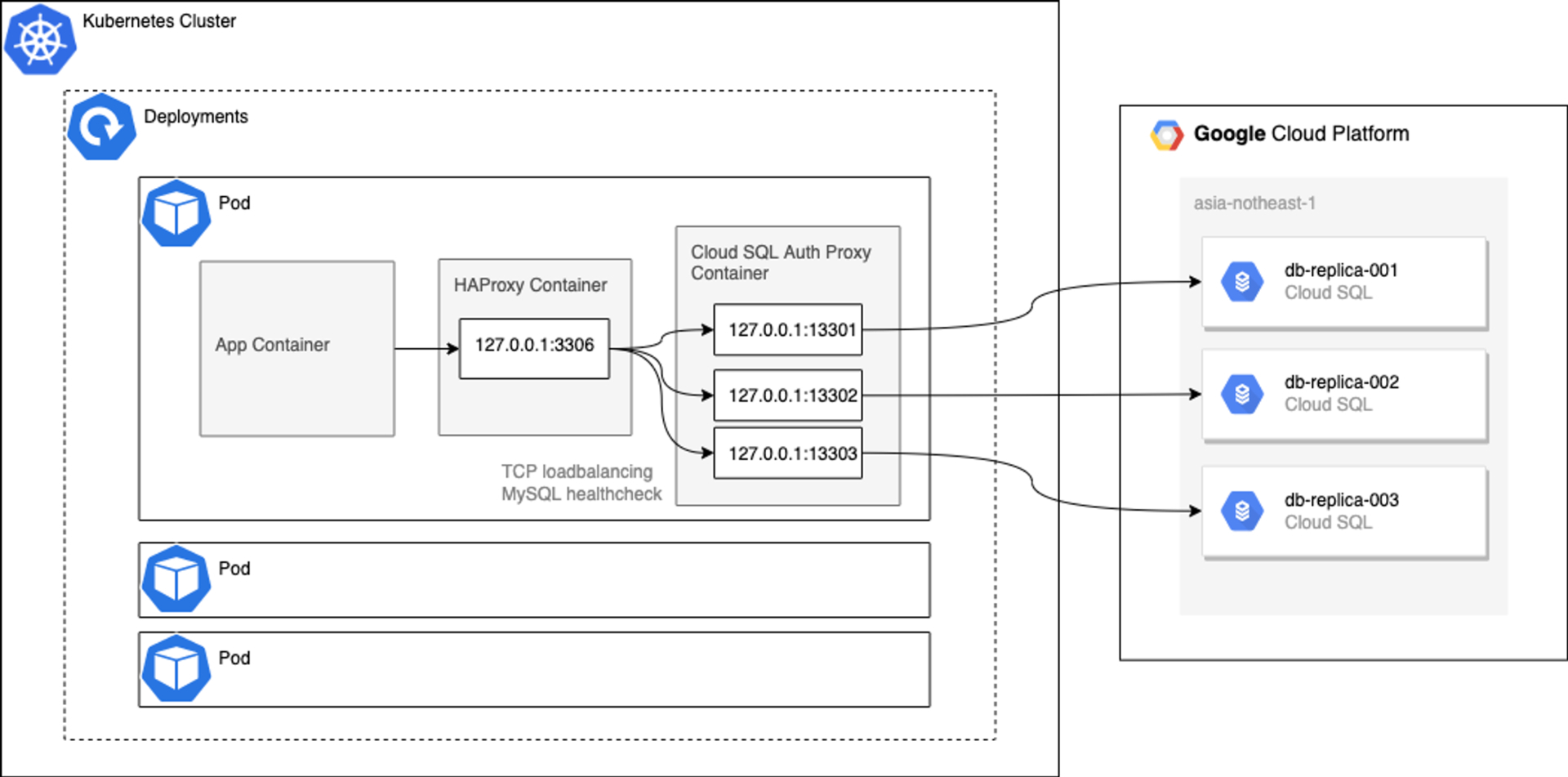
Docker Composeと大きく変わらないものの、不要なものは削っています。
アプリケーションコンテナから 127.0.0.1:3306 で参照エンドポイントを構成出来るよう構成します。設定方法のサンプルとして、deploymentsとHAProxyのconfigmapを記載します。
deployments例
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
spec:
replicas: 1
template:
metadata:
labels:
app: myapp
spec:
containers:
- name: app
ports:
- containerPort: 8080
name: http
protocol: TCP
# アプリケーション設定は割愛
- name: cloudsqlproxy
args:
- /cloud_sql_proxy
- -instances=your-project:asia-northeast1:db-replica-001=tcp:13301,your-project:asia-northeast1:db-replica-002=tcp:13302,your-project:asia-northeast1:db-replica-003=tcp:13303
envFrom:
- secretRef:
name: cloudsql-env
image: gcr.io/cloudsql-docker/gce-proxy:1.30.0
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /var/run/secret/cloud.google.com
name: gcp-secrets
- name: haproxy
image: haproxy:2.5-alpine
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /usr/local/etc/haproxy
name: haproxy-config
volumes:
- name: gcp-secrets
secret:
defaultMode: 420
secretName: myapp-gcp-secrets
- configMap:
defaultMode: 420
name: myapp-haproxy-config
name: haproxy-config
Cloud SQLAuth ProxyのサービスアカウントはsecretからvolumeMountで設定します。
HAProxyの設定は後述しますが、configmapからvolumeMountで読み込みます。
コンテナ間通信、リッスン範囲
cloud_sql_proxy コマンド引数の -instances で指定している箇所ですが、docker composeではコンテナ間通信のために以下の設定をしていました
=tcp:0.0.0.0:13301
cloud_sql_proxyの起動オプションについて細かい挙動はドキュメントに記載がありますが、TCPポートを利用する場合のデフォルトでは localhost としてリッスンします。Kubernetesでサイドカー構成する場合はpod内に閉じている方が好ましいため以下のように記載しています。
=tcp:13301
configmap例
HAProxyの設定はconfigmapで設定します。
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: myapp
name: myapp-haproxy-config
data:
haproxy.cfg: |
global
log stdout format raw local0
defaults
log global
retries 3
timeout connect 10s
timeout client 1m
timeout server 1m
timeout check 10s
maxconn 3000
listen mysql
bind 127.0.0.1:3306
mode tcp
option mysql-check user healthcheck
balance roundrobin
server replica-001 127.0.0.1:13301 check port 13301
server replica-002 127.0.0.1:13302 check port 13302
server replica-003 127.0.0.1:13303 check port 13303
ポイントとしては以下3点です
- ログを標準出力に出す
- listen範囲を最小限にする
- stats無効化
docker-composeでも標準出力に出す設定を入れていますが、Kubernetesの場合も同様です。fluentbitなど任意のログコレクターでログを拾わせる事が出来るので、標準出力に出しています。
サイドカー構成の場合はpod外からアクセスする必要が無いため、listen範囲は最小限に削る事が出来ます。Cloud SQL Auth Proxyもpod内部通信のみlistenする設定を入れているので、loopback ip(localhost)を指定して接続する形になります。
ログ以外にモニタリングする目的が現時点では無いためstatsは無効化する事にしています。
おわりに
HAProxyとCloud SQL Auth Proxyをサイドカーとして構成する例を紹介いたしました。厳密な性能評価は実施していませんが、pod内通信は1台の物理マシンで完結しているため、実質的なネットワークオーバーヘッドは極小さいものと考えています。
古くから存在するHAProxyを掘り起こす形で検証しましたが、枯れきったプロダクトではなく時代に合わせて変化している事が分かり、テクノロジーの温故知新と言える一例と感じました。
DB参照アクセスの負荷分散手法の一例として、参考になれば幸いです。