はじめに
SREグループの古越です。GOでは多くのプロダクトでAurora PostgreSQLを利用しています。Aurora PostgreSQLは標準で多くのCloudWatchメトリクスを出力しており、ほとんどのユースケースに対応できる可観測性があります。しかし、PostgreSQLの詳細なパフォーマンス指標は十分にサポートされていないため、一部ユースケースで不便を感じることがあります。
例えば、以下のようなケースです。
- テーブルごとのレコード数やデータ量、更新頻度を把握したい
- テーブルロックの発生頻度を把握したい
- ユーザーごとのプロセス数やクエリのレイテンシを表示したい
GOではオブザーバビリティ基盤としてGrafanaを使用しています。GrafanaはPrometheusとの親和性が高いため、何らかのPrometheus Exporterを使用することでこれまで手が届かなかった部分の可観測性を向上させることができます。 今回はPrometheus Exporterの一つであるpostgres_exporterを導入してみましたので、使い方を紹介します。
postgres_exporterの概要
Prometheus Exporterの概略とExporterの一つであるpostgres_exporterについて簡単に説明します。
Prometheus Exporterとは
postgres_exporterを説明する前に、Prometheus Exporterについて説明します。Prometheus Exporterとは、特定のサービスやアプリケーションからメトリクスを収集し、Prometheusが取り込める形式に変換するツールの総称です。有名なExporterとしてOS情報を読み込むnode_exporterがあります。
Prometheus Exporterのイメージ図

PrometheusのServerとExporterの動作 - Prometheus Server : データ収集の主体。登録されているExporterに対しスクレイピングを行いメトリクスを収集・保存する - Prometheus Exporter : 受動的に動作。サーバーからスクレイピング(HTTPリクエスト)を受けると登録済みの何らかのシステムのデータを取得し、Prometheusデータ形式で応答する
Prometheus Serverが主体となって動くため、Exporterを追加する場合はPrometheusサーバーにスクレイピング設定を入れる必要があります。 対象のExporterの数が多い場合は管理が煩雑になるため、Prometheusのサービスディスカバリを設定することでサーバー側の設定を省略することができます。 適切に設定しておけば、Exporterの数が増えても自動的にメトリクスのスクレイピングが開始されるため、導入時にはサービスディスカバリも含め設定することで後の運用が楽になります。
Prometheusコミュニティで管理されるものとサードパーティ製のExporterがあり、コミュニティで管理されるPrometheus Exporterは下記から確認することができます。
https://prometheus.io/docs/instrumenting/exporters/
postgres_exporterとは
postgres_exporterは、Prometheusコミュニティによって管理されるExporterの一つで、PostgreSQLデータベースのパフォーマンスメトリクスをPrometheusに出力できるツールです。コンテナ版が提供されているため、Kubernetes上でPodとして立ち上げることも容易です。
ユースケースごとの構成例
大まかに2種類の使われ方が想定されます。
- Kubernetes上のPostgreSQLサーバーのサイドカーとして起動する
- 外部のPostgreSQLサーバーを監視するExporterコンテナを立ち上げる

今回の記事ではAurora PostgreSQLを対象としているため、2の構成を前提とします。
収集するメトリクス
メトリクスはPrometheusによって定期的にスクレイプされるため、Grafanaなどの可視化ツールを用いて監視・アラート化が可能になります。postgres_exporterはPostgreSQLのクエリで見ることができる pg_* システムビューを元にしたメトリクスを収集します。
exporterが収集しているシステムビュー - pg_stat_databaseビューの各種カウンタ - pg_stat_activityビューのユーザーごとのカウンタ - pg_stat_user_tablesビューのカウンタ - pg_locksビューのロックモードごとのカウンタ - などなど...
収集できるメトリクスは単に増えるだけのカウンタが多く、そのままグラフ化しても右肩上がりか横ばいで使い勝手の悪いものが多いです。しかし、PromQLを使って工夫すると以下のような値を算出してグラフ化したりアラート化することができます。
postgres_exporter利用例 - テーブルごとのデータサイズやレコード数推定値 - テーブルごとのinsert/update/deleteクエリで変更された行数 - インデックスのヒット率や使用頻度 - DBユーザーごとのレイテンシ - テーブルごとのバッファキャッシュヒット率 - ロックモードごとのテーブルロック発生数
postgres_exporterのコレクター
postgres_exporterは収集可能なメトリクスの種類が多いため、「コレクター」という単位でメトリクス収集処理がグループ化されており、コレクター単位でメトリクス収集のon/offをコントロールできます。コレクターのon/offはプロセス起動時の引数および環境変数で設定可能です。欲しいけれどデフォルトでoffになっているものや、不要だけれどデフォルトでonになっているものがあるため、内容を確認してon/offを切り替えると良いでしょう。PostgreSQLサーバーの設定やバージョンによって取得可能なメトリクスが異なったり、構成によってはエラーが出続けたりサーバーに負荷を与えることもあります。本番環境へ導入する前には、必要なコレクターのみ許可するようにチューニングすることを推奨します。
postgres_exporter GitHubリポジトリ上ではメトリクスの詳細が文章化されていません。コレクターごとにどのようなメトリクスがあるかはコレクターのソースを確認するか、実際に動かしてメトリクスを確認すると良いでしょう。この後の項目で簡単な動かし方を紹介します。
postgres_exporterの試用方法
ここではdockerでpostgresサーバとpostgres_exporterを起動する例を紹介します。動かしてメトリクスを見てみましょう。
ローカル試験環境のイメージ図
docker上でローカルにこのような構成を作り、curlでメトリクスを取得してみましょう。

手順
docker-compose.yaml に以下のように記載します。
version: '3'
services:
# ----------
# PostgreSQL
# ----------
postgresql:
image: postgres:15
environment:
POSTGRES_DB: 'main'
POSTGRES_USER: 'postgres'
POSTGRES_PASSWORD: 'password'
# ----------
# Postgres Expoter
# ----------
postgres_exporter:
image: quay.io/prometheuscommunity/postgres-exporter
environment:
# PostgreSQL
DATA_SOURCE_URI: postgresql:5432/main?sslmode=disable
DATA_SOURCE_USER: postgres
DATA_SOURCE_PASS: password
depends_on:
- postgresql
ports:
- "9187:9187"
docker composeを起動します。
docker compose up -d
postgres_expoterにhttpリクエストを投げてメトリクスを確認してみましょう。
curl -s http://localhost:9187/metrics
ここで応答されるメトリクスはpostgres_exporter自身の状態を示すメトリクスが含まれるため少々見づらいです。下記のような pg_ から始まるメトリクスを確認出来ればOKです。
...
# HELP pg_database_size_bytes Disk space used by the database
# TYPE pg_database_size_bytes gauge
pg_database_size_bytes{datname="main"} 7.631663e+06
pg_database_size_bytes{datname="postgres"} 7.631663e+06
pg_database_size_bytes{datname="template0"} 7.471619e+06
pg_database_size_bytes{datname="template1"} 7.705391e+06
...
コレクターのon/offや取得出来るメトリクスを簡単に確認出来るため、導入前には一度触れてみると良いかと思います。
postgres_exporterのデプロイ, Aurora PostgreSQL向け設定
postgres_exporterをKubernetes上でデプロイし、Aurora PostgreSQLをモニタリングする構成例や手順について説明します。
構成イメージ図
おおまかに以下のイメージで作ります。

ポイント
- モニタリング用ユーザを作成しユーザ情報をSecretに格納
- DBインスタンス1台に対してpostgres_exporter 1podを起動(Single-Target x DB Instance)
Single-Target構成が良い理由については後で解説します。
設定手順
以下のようなAurora Clusterがある前提で設定例を紹介します。
| 項目 | 値 |
|---|---|
| Aurora Cluster | myqpp-dev |
| Aurora DB Instance | myqpp-dev-0, myqpp-dev-1 |
| Database | main |
1. DB用ユーザの作成
postgres_exporter というログイン可能なRole(USER)を作成します。権限は定義済みロールの pg_monitor を付与するのが最小権限で良いと思います。
CREATE USER postgres_exporter WITH PASSWORD 'yourpassword'; GRANT pg_monitor TO postgres_exporter;
必要に応じてデータベースやテーブルの参照権限を付与すると良いでしょう。
2. secret, deployment作成
kubernets上に設定する例として、secretとdeploymentの例を書きます。 GOではhelmで適用していますが、現場毎にhelmの作法が違うかと思うのでhelmについては省略します。
Secret
postgres_exporterでは DATA_SOURCE_USER, DATA_SOURCE_PASS 環境変数に接続情報を記述出来ます。 以下のようなsecretを設定し、pod起動時の環境変数にセットします。
apiVersion: v1 kind: Secret metadata: name: postgres-exporter-cluster-auth-myapp-dev labels: app: postgres-exporter db-app: myapp db-cluster: myapp-dev type: Opaque stringData: DATA_SOURCE_USER: postgres_exporter DATA_SOURCE_PASS: yourpassword
Deployment
exporter podを展開するdeploymentは以下のように設定します。
apiVersion: apps/v1 kind: Deployment metadata: name: postgres-exporter-myapp-dev-0 labels: app.kubernetes.io/name: postgres-exporter app: postgres-exporter db-app: myapp db-cluster: myapp-dev db-instance: myapp-dev-0 spec: replicas: 1 selector: matchLabels: app.kubernetes.io/name: postgres-exporter app: postgres-exporter db-app: myapp db-cluster: myapp-dev db-instance: myapp-dev-0 template: metadata: annotations: prometheus.io/path: /metrics prometheus.io/port: "9187" prometheus.io/scrape: "true" labels: app.kubernetes.io/name: postgres-exporter app: postgres-exporter db-app: myapp db-cluster: myapp-dev db-instance: rds-myapp-dev-0 spec: containers: - name: postgres-exporter image: quay.io/prometheuscommunity/postgres-exporter:v0.15.0 imagePullPolicy: IfNotPresent ports: - containerPort: 9187 name: http protocol: TCP envFrom: - secretRef: name: postgres-exporter-cluster-auth-myapp-dev env: - name: DATA_SOURCE_URI value: "rds-myapp-dev-0.xxxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com:5432/main?sslmode=disable" livenessProbe: httpGet: path: / port: http readinessProbe: httpGet: path: / port: http resources: limits: memory: 32Mi requests: cpu: 10m memory: 32Mi
ポイント
- annotationsにPrometheusサービスディスカバリ設定を記述する
- 後でメトリクスのリラベル処理のため、podのラベルにdb-cluster名やdb-instance名を書いておく
- DATA_SOURCE_URI にDBインスタンスエンドポイントを記載
2台目db instance分のdeploymentsはほぼdb-instance以外同じなので省略しますが、DB Instanceを追加する時に楽して出来るようにhelmなど構成しておくとよいかと思います。
3. prometheusのscrape_job設定
prometheus serverのscrape_configsに以下のようなジョブを追加します。
# postgres-exporter - job_name: 'postgres-exporter' scrape_interval: 1m kubernetes_sd_configs: - role: pod relabel_configs: # ----- only postgres-exporter ----- - source_labels: [__meta_kubernetes_pod_label_app_kubernetes_io_name] regex: postgres-exporter action: keep # ----- cluster metadata ----- - source_labels: [__meta_kubernetes_pod_label_db_cluster] regex: (.+) action: replace target_label: db_cluster - source_labels: [__meta_kubernetes_pod_label_db_instance] regex: (.+) action: replace target_label: db_instance
これによってこのスクレイピングジョブで取得したメトリクスに db_cluster , db_instance というラベルが付与されるようになり、PromQLでクエリする時にdb_clusterまたはdb_instance単位でグループ化出来るようになります。
仕込みとしては以上です。
備考: Single-TargetでDBインスタンスごとにPodを作る理由
DBインスタンスごとに設定する理由
AuroraにはCluster EndpointやReader Endpointがありますが、postgres_exporterを設定する場合はインスタンスエンドポイントに対して設定が必要です。
理由
1. postgres_exporterが取得するメトリクスのほとんどがサーバー固有の統計情報であり、PostgreSQL再起動時にリセットされる値であるため
2. PromQLのdelta、idelta関数など、前後の差を比較するクエリを書いている場合、時系列でサーバーが変わると意味のないグラフになるため
サーバー固有のメトリクスを収集するため、Cluster EndpointのフェイルオーバーやReader EndpointのDNSラウンドロビンとは相性が良くありません。 とはいえ台数が変動する場合に設定を更新する必要があるため、管理が煩雑な点はデメリットです。 例えばAurora Auto Scalingと併用する場合は、Writer:1, Reader:1の2台を固定DBインスタンスとして設定してサンプリングし、他は放って置く形で良いと思います。
Single-Target採用理由
postgres_exporterには1つのpostgres_exporterから複数のPostgreSQLサーバーを見るMulti-Target機能がベータ版で提供されていますが、今回は採用を見送っています。
Multi-Target機能では、postgres_exporterをデプロイした後、DBの接続設定をPrometheus Serverでコントロールする必要があります。DBインスタンス変動時にPrometheus Serverの更新が必要という点が、我々の環境と相性がよくなかったため採用を見送っています。
Single-Targetの場合、DBインスタンスをスケールアウトしたときにpostgres_exporterのpod(deployment)を追加する手間が増える点がデメリットですが、helmなどを用いれば数行追加するだけでPodを増やすように設定できます。仮にpostgres_exporterのメトリクス取得にトラブルがあっても、DBインスタンス単位で影響が最小化されるため、切り分けや対処が簡単です。postgres_exporterのCPU、Memoryリソースも少量で良いため、適切に構成すれば管理工数はさほど高くありません。
そういった背景からSingle-TargetでPodを並べる構成を採用しました。
PromQLとグラフ化の例
取得したメトリクスをPromQLを使ってグラフ化する例を簡単に紹介します。
サンプルとして社内利用しているRedashのバックエンドDBのグラフを紹介します。
テーブルごとのレコード数やデータ量、更新頻度を表示
pg_stat_user_tables由来のメトリクスを活用する事で可視化が可能です。
テーブル毎の推定レコード数
pg_stat_user_tables の n_live_tup カラムのメトリクスである pg_stat_user_tables_n_live_tup はテーブルごとの推定レコード数を見ることが出来ます。
この値はANALYZEによって更新される統計情報が情報元なので、厳密な値ではなく推定値になります。厳密な値は select count(*) from table を見る必要がありますが、数千万から数億レコードの膨大なデータを含むテーブルになると単なるレコード数のカウントを実行するのも時間がかかります。そんな時にこのメトリクスが活用出来ます。
PromQL
sum by(schemaname, relname) (
pg_stat_user_tables_n_live_tup{
job="postgres-exporter",
db_app=~"$db_app",
db_cluster=~"$db_cluster",
db_instance=~"$db_instance",
datname=~"$database",
schemaname=~"$schema",
relname=~"$table"
}
) > 0
グラフ化例
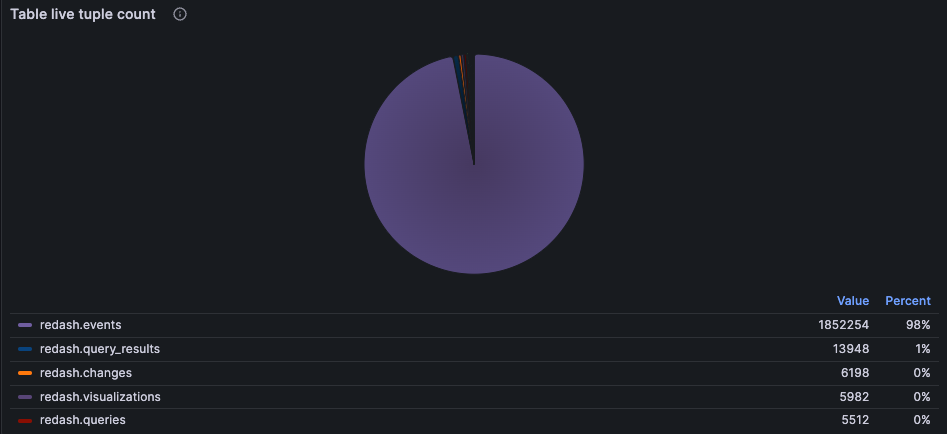
グラフ化の詳細は省きますが、円グラフで表示するとテーブル毎の重さが一目瞭然で良いかと思います。
テーブル毎のデータ量
pg_stat_user_tables_size_bytes を見ればPostgreSQLのdiskに保存される実体のデータサイズを見る事も出来ます。
PromQL例
avg by (relname, schemaname) (
pg_stat_user_tables_size_bytes{
job="postgres-exporter",
db_cluster=~"$db_cluster",
db_instance=~"$db_instance",
datname=~"$database",
schemaname=~"$schema",
relname=~"$table"
}
) > 0
グラフ化例
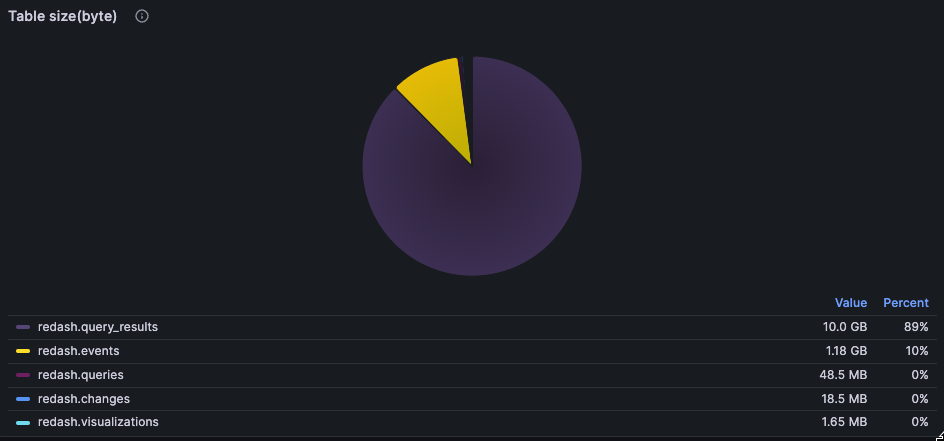
上述のレコード数グラフと比較すると1レコードのサイズ差が直感的に見えてきますね。
更新頻度
以下メトリクスはINSERT, DELETE, UPDATEのカウンタでテーブル単位でグループ化出来ます。
pg_stat_user_tables_n_tup_inspg_stat_user_tables_n_tup_delpg_stat_user_tables_n_tup_updpg_stat_user_tables_n_tup_hot_upd
例えば、ideltaで差分を出すクエリを書けば、テーブル毎にinsertされたレコード数の推移を表示出来ます。
PromQL
sum by(schemaname, relname) (
idelta(
pg_stat_user_tables_n_tup_ins{
job="postgres-exporter",
db_app=~"$db_app",
db_cluster=~"$db_cluster",
db_instance=~"$db_instance",
datname=~"$database",
schemaname=~"$schema",
relname=~"$table"
}[$__range]
)
) > 0
上記クエリを活用すると、更新行数の時系列グラフを表示出来るようになります。
グラフ化例

営業時間内に特定テーブルの更新頻度が高い事がなんとなくわかりますね。
テーブルロックの発生数を見る
pg_locks_count というメトリクスがそのまま使えます。ロックモード毎にグループ化出来るので、強いロックが長時間発生してないか確認することが出来ます。
PromQL例
sum by(mode) (
pg_locks_count{
job="postgres-exporter",
db_cluster=~"$db_cluster",
db_instance=~"$db_instance",
datname=~"$database"
}
) > 0
グラフ例
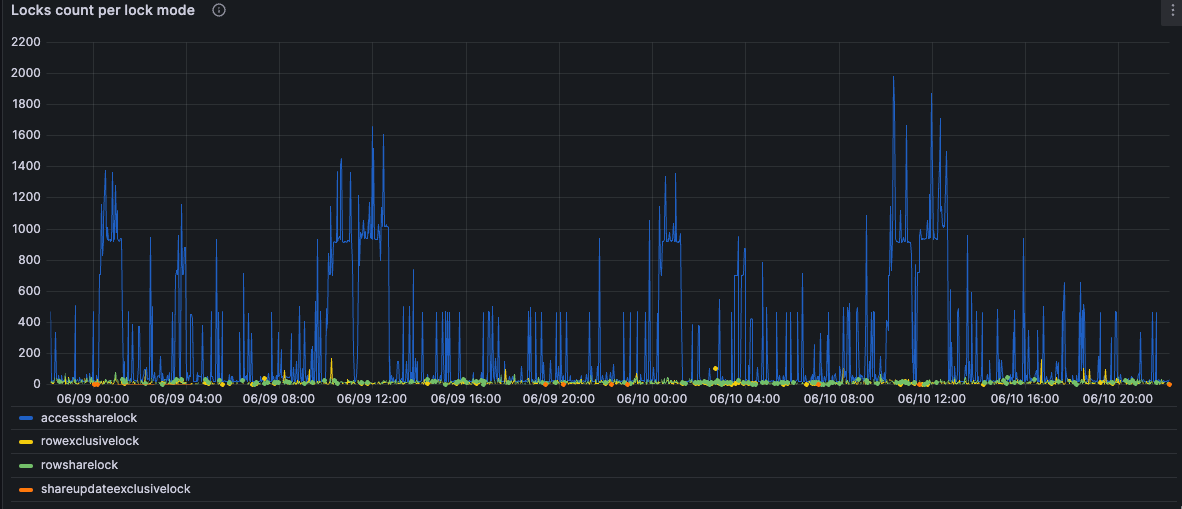
例えばこのグラフでAccessShareLockが有るのは問題ないですが、他のロックがたまに出てるのが気になりますね。 仮にAccessExclusiveLockが長時間続いてる場合は注意が必要です(selectと競合する最も強いテーブルロックであるため)。
このメトリクスを活用すれば、ロック数の推移から危険な兆候を読み取れるようになるかもしれません。 元のメトリクスがデータベース単位であるため、テーブル単位で状況を見れない点だけは残念です。
QPS (Query Per Sec)
pg_stat_database_xact_commit , pg_stat_database_xact_rollback メトリクスを活用することでQPSを出すことが出来ます。
PromQL
sum(irate(
pg_stat_database_xact_commit{
job="postgres-exporter",
db_cluster=~"$db_cluster",
db_instance=~"$db_instance",
datname=~"$database"
}[$__range]
))
+
sum(irate(
pg_stat_database_xact_rollback{
job="postgres-exporter",
db_cluster=~"$db_cluster",
db_instance=~"$db_instance",
datname=~"$database"
}[$__range]
))
グラフ化例
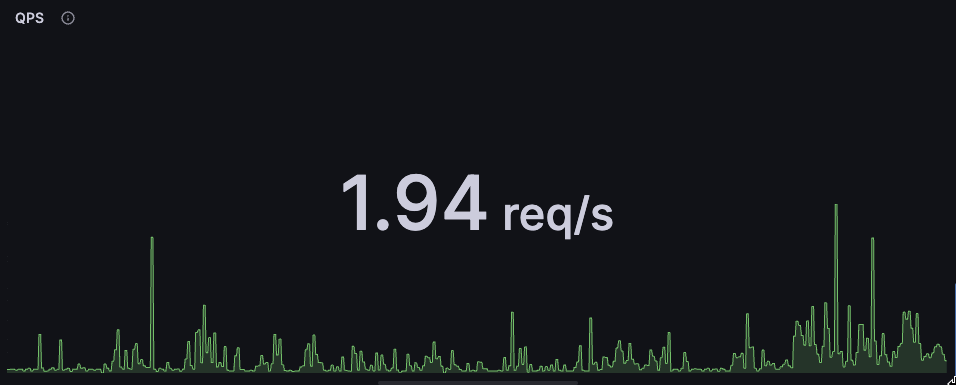
Active Transaction Latency (per user)
pg_stat_activity_max_tx_duration メトリクスを使うと、ユーザ毎のトランザクションの長さを出す事が出来ます。
PromQL
sum by(usename) (
pg_stat_activity_max_tx_duration{
job="postgres-exporter",
db_cluster=~"$db_cluster",
db_instance=~"$db_instance",
datname=~"$database"
}
) > 0
例としてはRedashではなく、Redashから突かれているDBのグラフが面白かったため紹介します。
グラフ例

redash_readonly というユーザを作成してRedashからクエリを流せるようにしているのですが、明らかにredash_readonlyユーザのトランザクションが長くなっていますね。 応答まで非常に時間かかる1クエリが滞留しているとこのようなグラフになります。
まとめ
postgres_exporterを使ってAurora PostgreSQLの可観測性を高める方法を具体的に紹介しました。 postgres_exporterを使えばPostgreSQL内部のテーブル単位のメトリクスといった、より詳細なポイントを可視化する事が出来ます。 今回紹介したメトリクスは一例で、indexチューニングに活用可能なメトリクスもあります。また機会があれば、利用可能なメトリクスやGrafanaのダッシュボードについて紹介しようと思います。