AI技術開発部アルゴリズムグループの島越です。今回は、アルゴリズムグループの老木と島越がGoogle Cloud Day: Digital' 21のブレイクアウトセッションで「AI を用いたタクシー配車における BigQuery 徹底活用術」というタイトルで登壇しましたので、その内容について紹介させていただきます。なお、当日の動画はGoogle Cloud Dayのサイトで視聴することができます。また、スライドについてもこちらに公開されています。ブログについては、老木が発表した部分を前半パート、島越が発表した部分を後半パートとして紹介させていただきます。この記事は前半パートの記事となっています。
はじめに
Google Cloud Day: Digital' 21 は 2021/05/25 から 2021/05/27 までオンライン開催された、Googleが主催のデジタルカンファレンスです。ブレイクアウトセッションでは、様々な業種の会社におけるGoogle Cloudの活用事例について発表されます。今回は、我々もこのブレイクアウトセッションに登壇し、タクシー配車アプリ「GO」で提供しているAIを用いた機能におけるBigQueryの活用例についてお話しさせていただきました。
弊社が提供するタクシー配車アプリ「GO」では、日間数億件オーダーの車両動態情報を蓄積し、分析や開発に役立てています。今回はそれらのデータを用いたサービスの一例として「AI予約」を例に
- 数万台のタクシーの位置情報の複雑な集計処理
- AIの学習・推論処理
をBigQuery上で完結することで、エンジニアリングコストの削減とリアルタイム処理を実現しました。本ブログでは、その登壇内容について前半後半に分けて紹介させていただきます。
AI予約
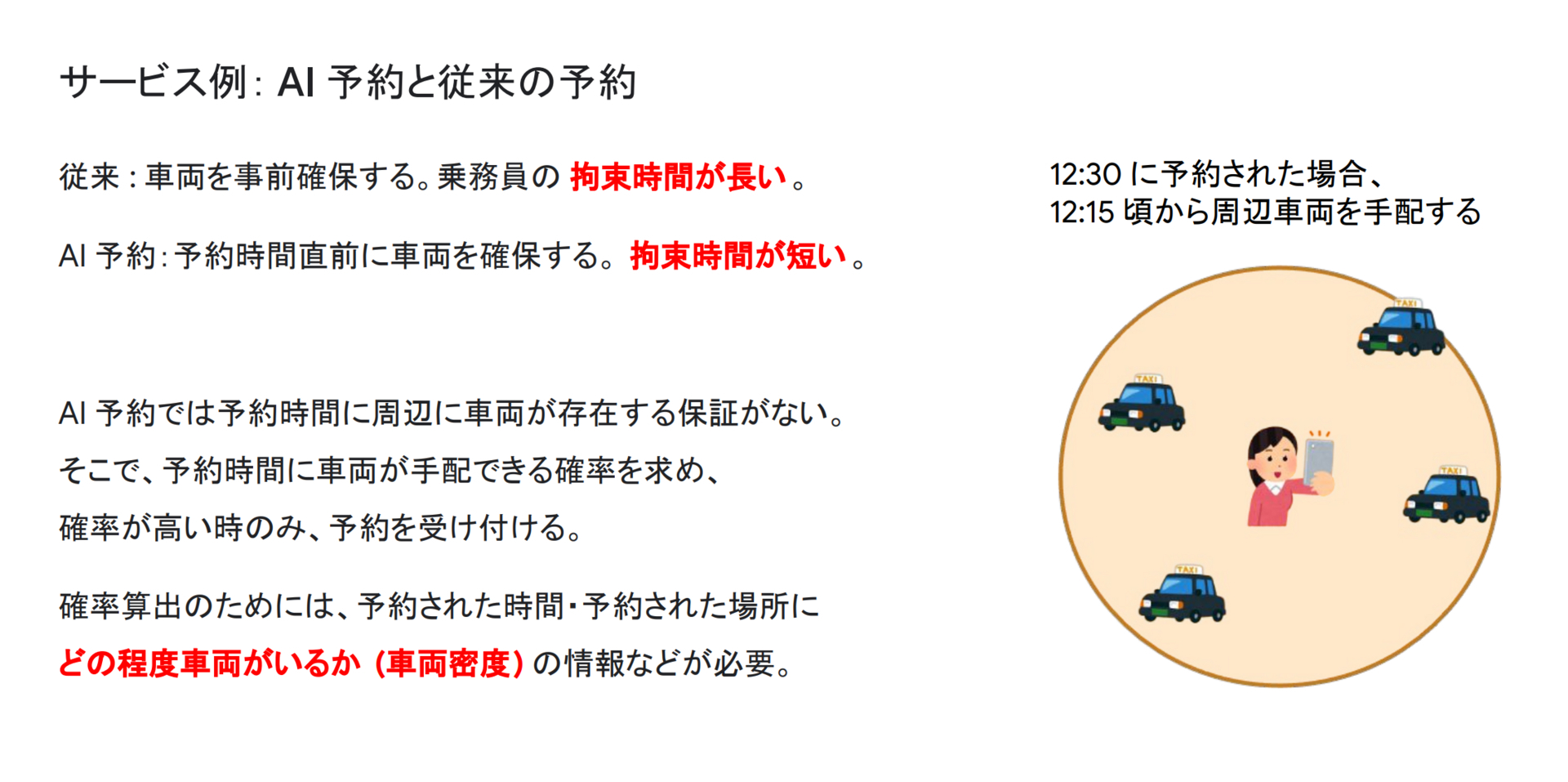
今回題材とするAI予約についてご紹介します。従来のタクシー予約にはいくつかの課題がありました。そのうちの一つに、タクシー会社が予約時間に確実に配車を行うために、早いタイミングで乗務員を確保しなければならないという問題がありました。早いタイミングで確保することで、乗務員の拘束時間が長くなってしまい、営業上のロスが大きく、営収にも影響が出てしまっていました。
そこで我々は前もって車両の位置情報データから、ユーザが予約したい時間・場所においてどれくらいの車両が確保できそうかを予測し、その車両数からタクシーを手配できる確率を算出する機能を作成しました。これにより、算出した配車確率が高い場合はユーザから予約を受け付け、車両は予約時間直前に確保することで、乗務員の拘束時間を短くすることが可能となりました。更に、車両数についても精度良く予測することで、配車成功率も非常に高い水準を保っています。この機能を「AI予約」と呼びます。(AI予約に関して詳しく知りたい方は、こちらの記事もご覧ください。)
このAI予約に関して、位置情報データを集計する部分・その集計したデータから機械学習モデルが配車可能な車両数を予測する部分をBigQuery上で完結させています。
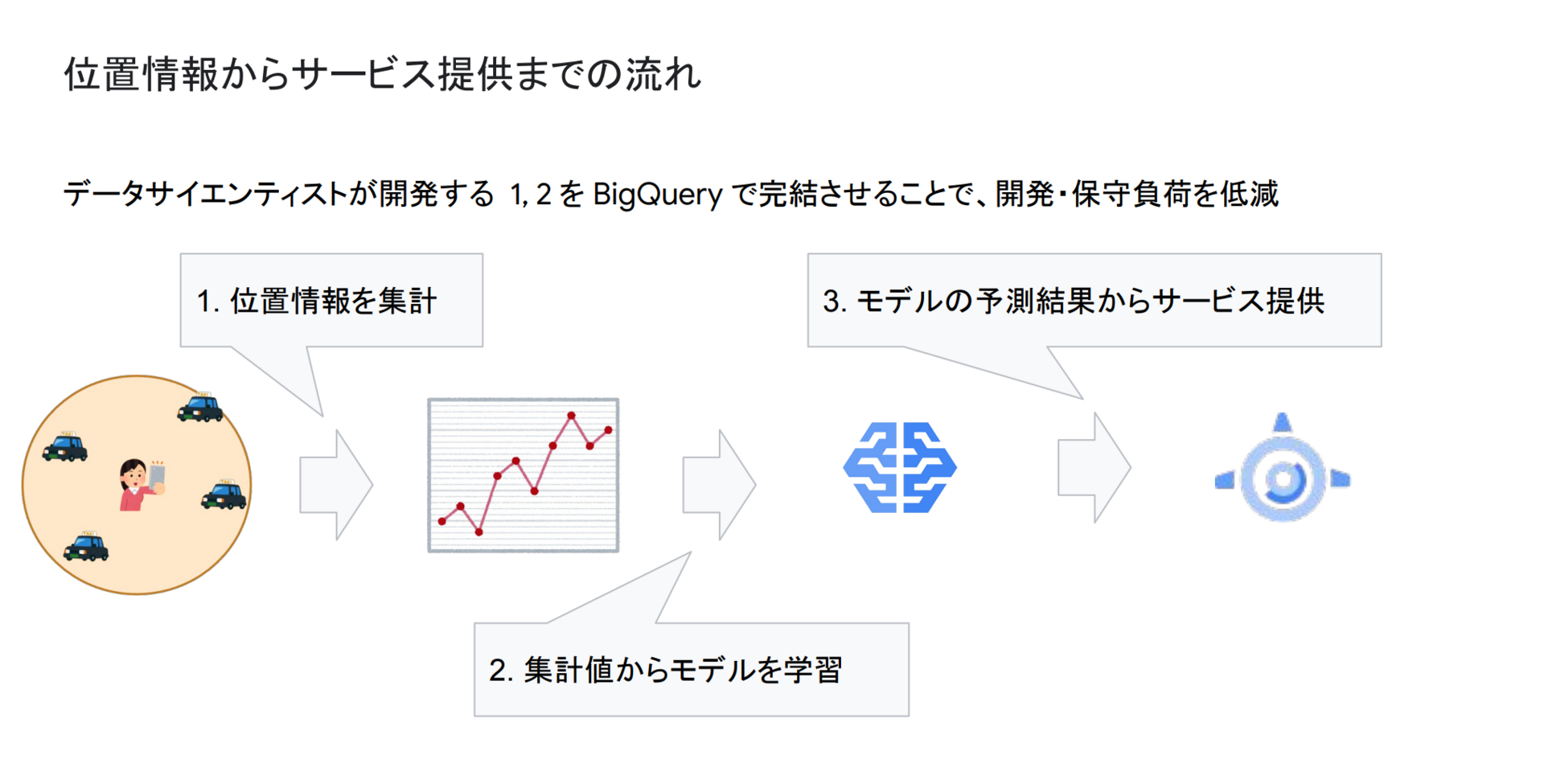
BigQueryによる集計処理
では、どのようにしてこれらの集計処理を行なっているのかを説明していきます。AI予約においては、ある程度のリアルタイム性が必要となるため、15分毎にどこに何台の配車可能車両が存在したかを集計・予測しています (スライド図)。車両の動態データは数秒単位で蓄積され、更に数万台分あるため、かなりの計算能力が必要になります。そこで、BigQueryを用いることで並列処理を簡単に実現しています。しかし、動態データのような複雑なデータを「BigQuery上で」「リアルタイムに」行うには、以下のようなことが必要になります。
- 複雑な処理をSQLで実装する
- BigQuery上でリアルタイム性を保つためのエンジニアリング
これらの二つの課題について、どのようにして解決しているかを以下で述べます。

複雑な処理の実装
BigQueryにはBigQuery GISという機能があり、位置情報データの処理を高速に簡単に記述することができます。このBigQuery GISを我々もフル活用しています。

また、スライドの右図のように車両は重複する時間帯に色々な場所に存在するため、それらの集計処理は非常にややこしくなります。しかし、BigQueryの分析関数を用いれば、簡単にかつ高速に記述することができます。他にも工夫として、SQLで書ききれない複雑な処理はjavascript UDFを用いたり、ARRAY / STRUCT なども積極的に使用しています。SQLで複雑な処理を記述すると可読性が低くなり、バグを埋め込みやすくなってしまうため、各種クエリにASSERTを入れることでバグを埋め込みにくくする工夫なども行なっています。
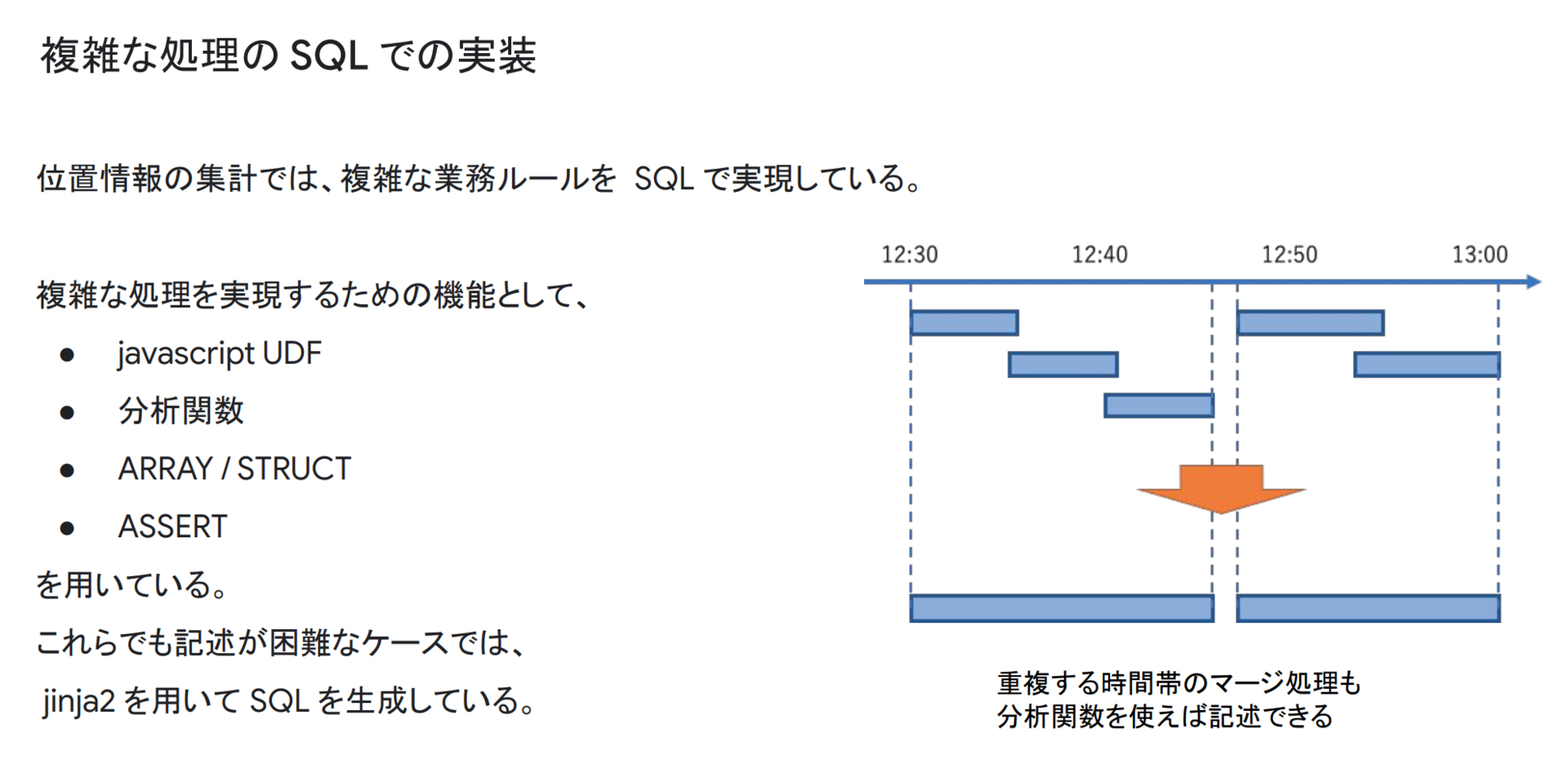
更に、我々は Jinja2テンプレートを用いてSQLを記述することで、パラメータの外出し、ループを必要とする処理、繰り返しになる記述の省略などを行い、可読性の向上と複雑な処理の実装を行なっています。

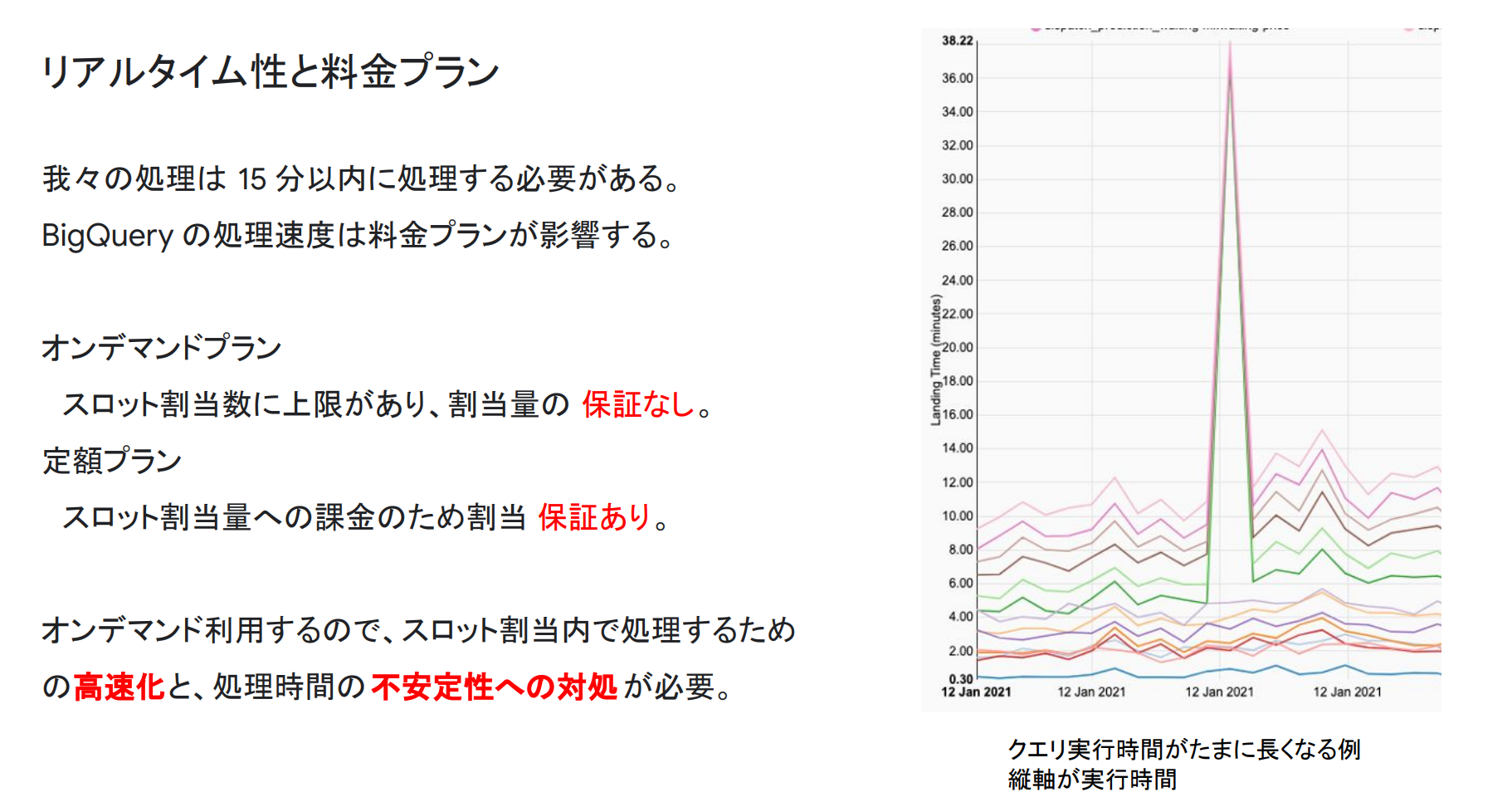
リアルタイム性
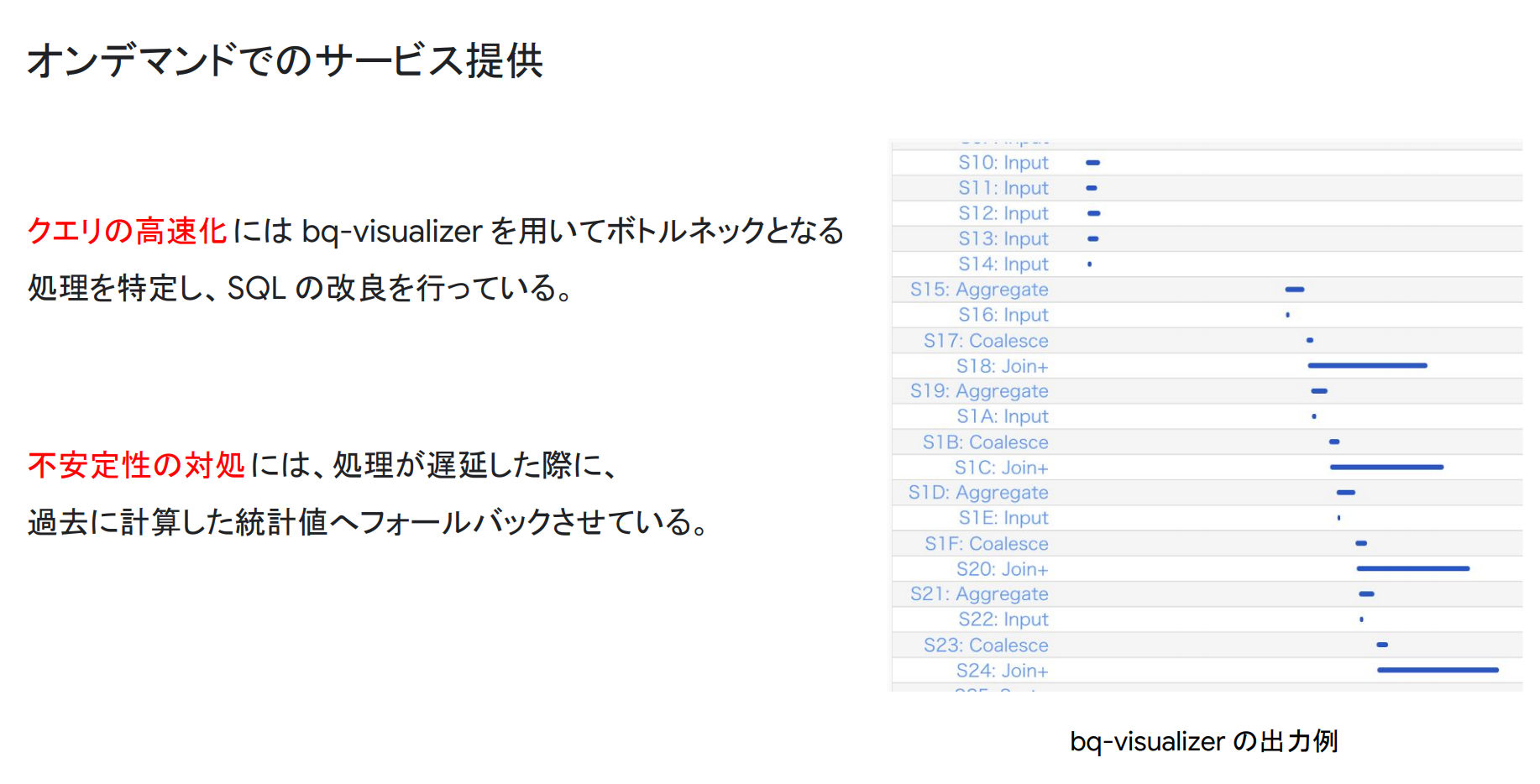
弊社では、BigQueryのオンデマンドプランを使用しているため、スロットの割当数に制限があります。そのためスロットの割当内で処理するための高速化や、処理時間の不安定性への対処が必要となります。
BigQueryで高速化を行う際には、bq-visualizerというツールを使うのが便利です。少しクセはありますが、慣れればSQLのボトルネックとなる処理を特定することができるので、それがJOINの部分なのであれば「JOIN前のテーブルを小さくする」などの高速化を行うことができます。
また、BigQueryの処理時間が予想以上に時間がかかったとしてもサービスが止まらないように過去の統計値を用いることで、BigQueryの不安定性に対処しています。
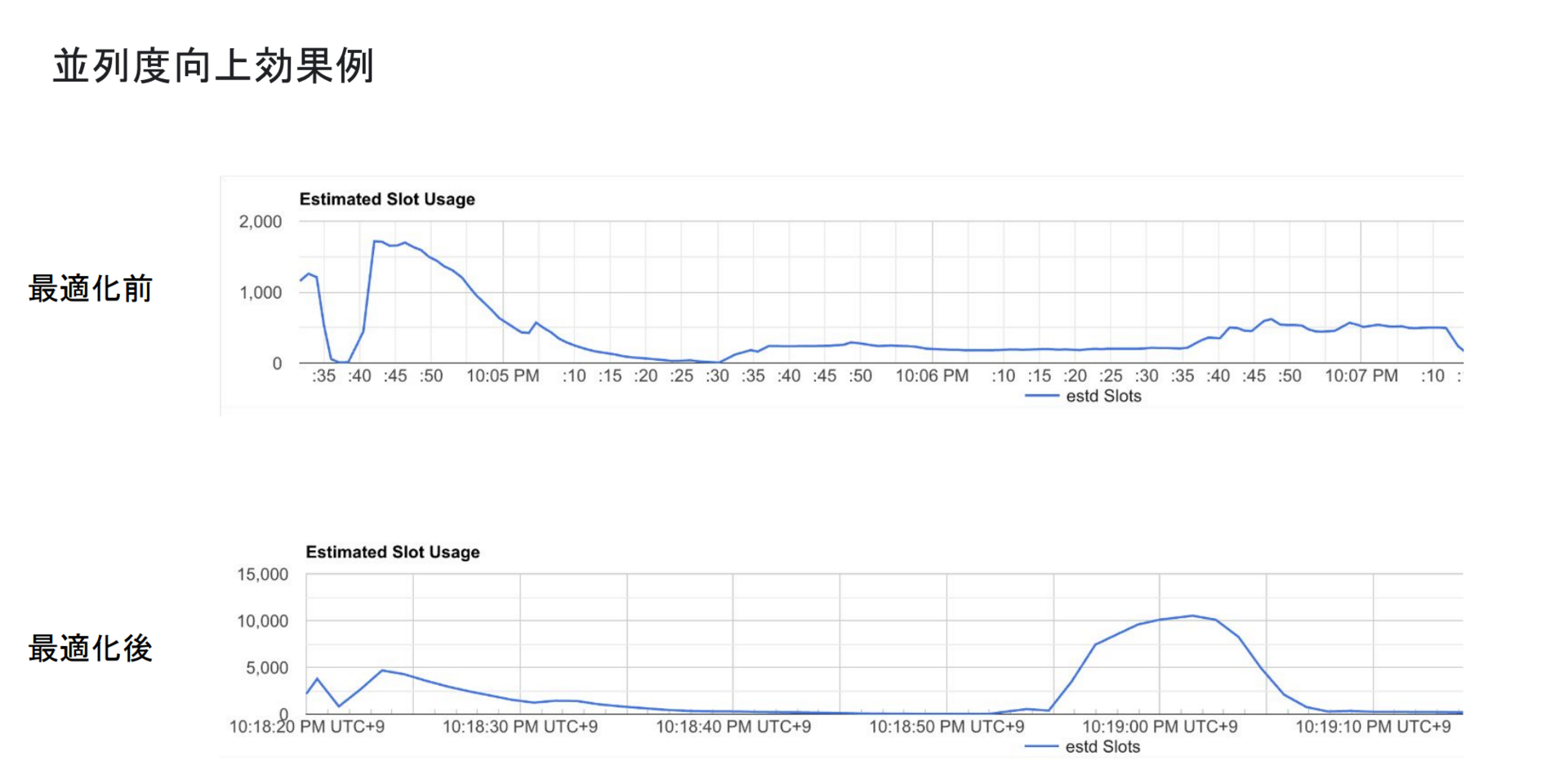
ここで一つBigQueryの特殊な高速化例について紹介します。次のスライドの例のように、重い処理を行う前に意図的にテーブルを分割して読み込むことで、BigQueryの並列度を上げるというテクニックがあります。これにより、並列読み込みをする前は2000程度しか使われていなかったスロット数が10000程度まで使われるようになり、SQL実行が遥かに高速になります。

おわりに
今回は、Google Cloud Day: Digital' 21 で老木と島越が登壇した内容について前半部分について紹介しました。前半パートでは、弊社が提供するAI予約サービスについて紹介と、そのサービスを提供するためにBigQuery上でどのような処理上の工夫を行なっているかの紹介を行いました。後半パートでは、AI予約におけるBigQuery MLの活用について紹介しますので、そちらも是非ご覧ください!