AI技術開発部アルゴリズムグループの島越です。前回は、アルゴリズムグループの老木と島越がGoogle Cloud Day: Digital' 21 で登壇した内容について、BigQueryの活用例についてまで紹介しました。こちらの後半パートでは、BigQuery ML の活用例について紹介していきます。当日の動画はGoogle Cloud Dayのサイトに、スライドについてはこちらに公開されています。
はじめに
前回の記事では主に。AI予約についての紹介とAI予約を提供するためにBigQuery上でどのような処理上の工夫を行なっているかの紹介を行いました。後半であるこの記事では、AI予約の予測機能部分についてBigQuery MLを用いてどのように処理を行なっているか、また、BigQuery MLの実務で用いる際の課題などについて紹介させていただきます。
BigQuery ML による予測
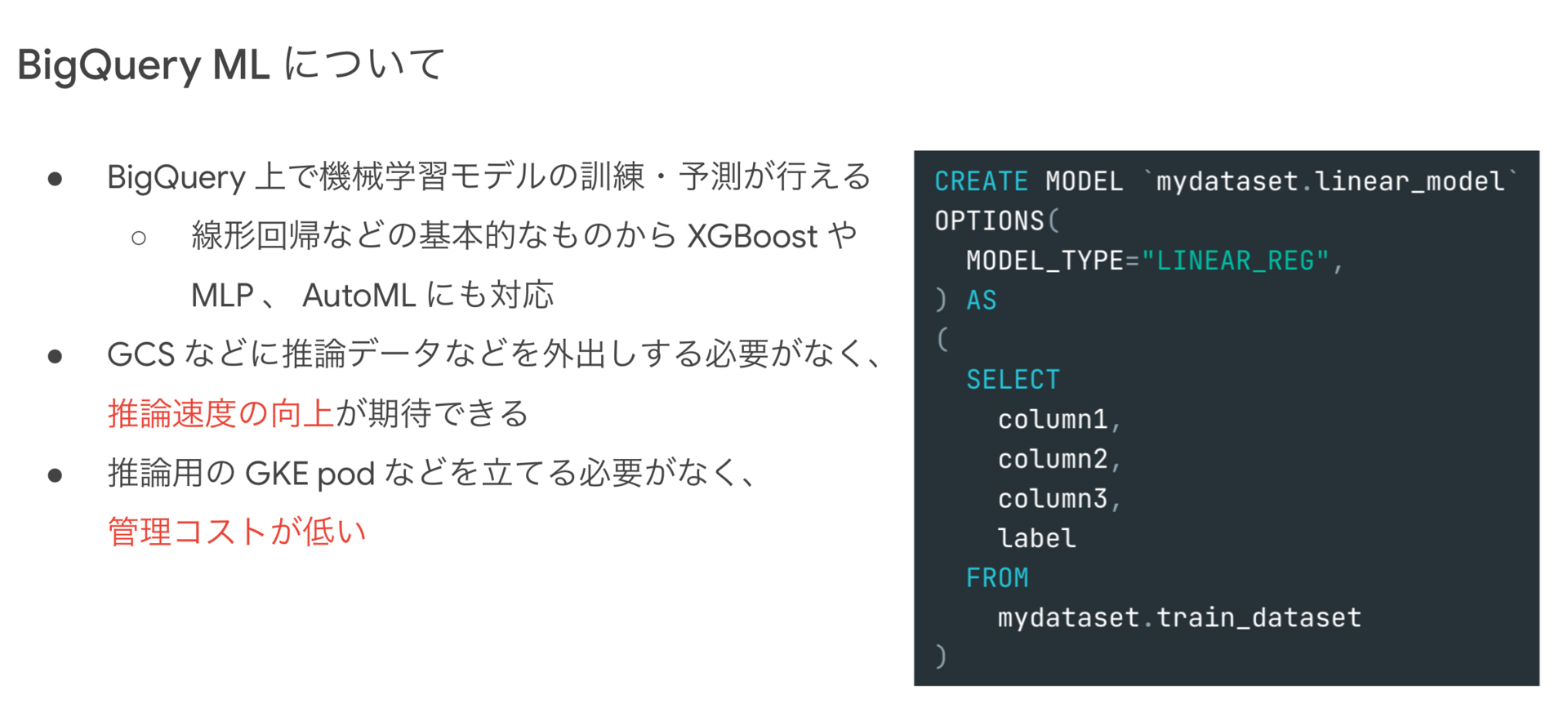
BigQuery ML とはGoogleが提供するBigQuery上の機能で図のクエリのように書くだけで機械学習アルゴリズムの訓練と予測を行うことができます。メリットとしては、以下のようなことが考えられます。
- BigQuery で計算した特徴量を一度GCSに置いて、それを用いて予測するといった中間処理が不要になる。
- GKEなどで推論用APIを立てる必要がなくなる
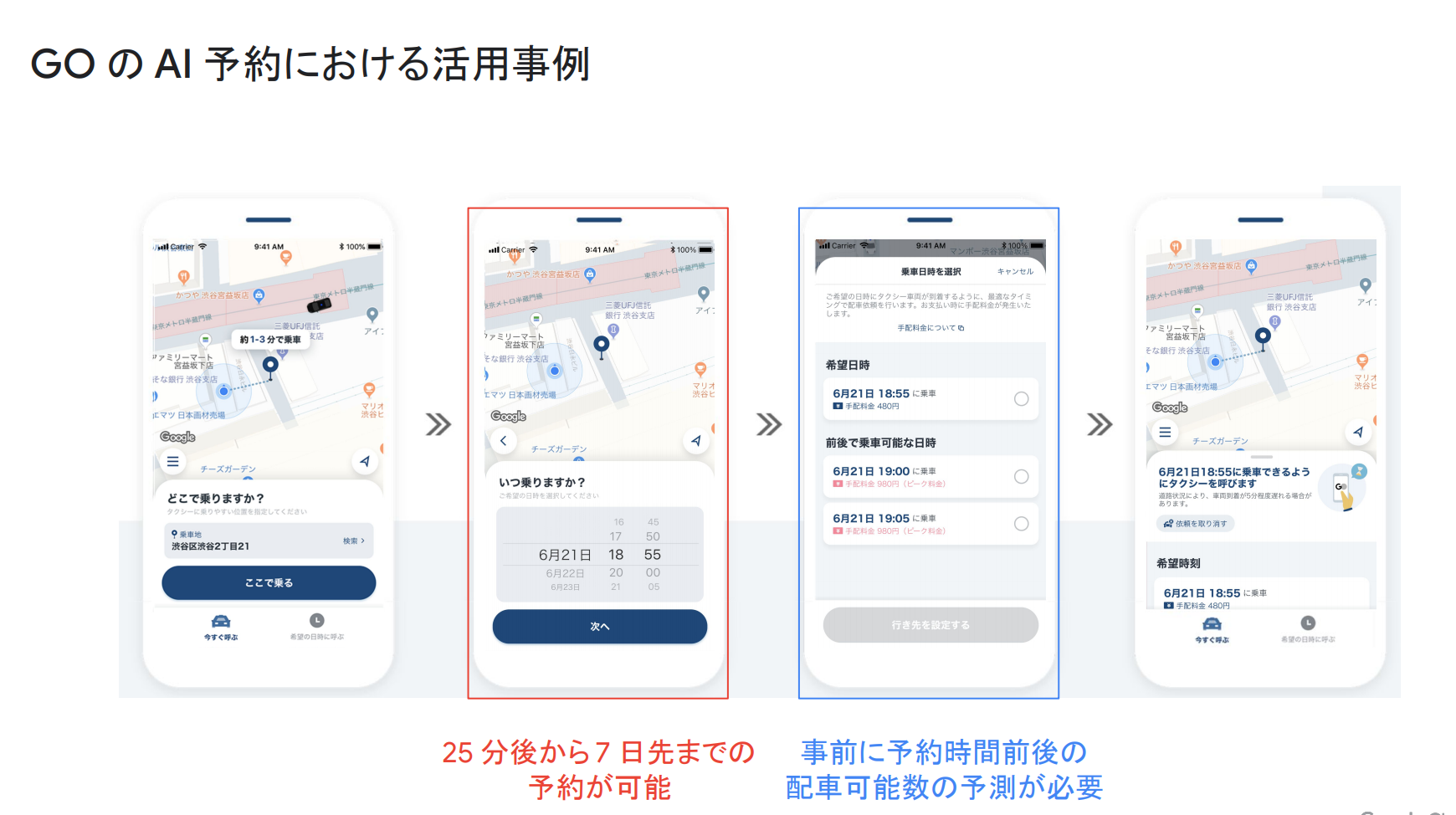
AI予約では、25分後から7日後までの予約が可能となっており、事前に予約時間前後の配車可能な車両数の予測が必要となってきます。この予測を行う部分に我々は BigQuery ML を用いています。
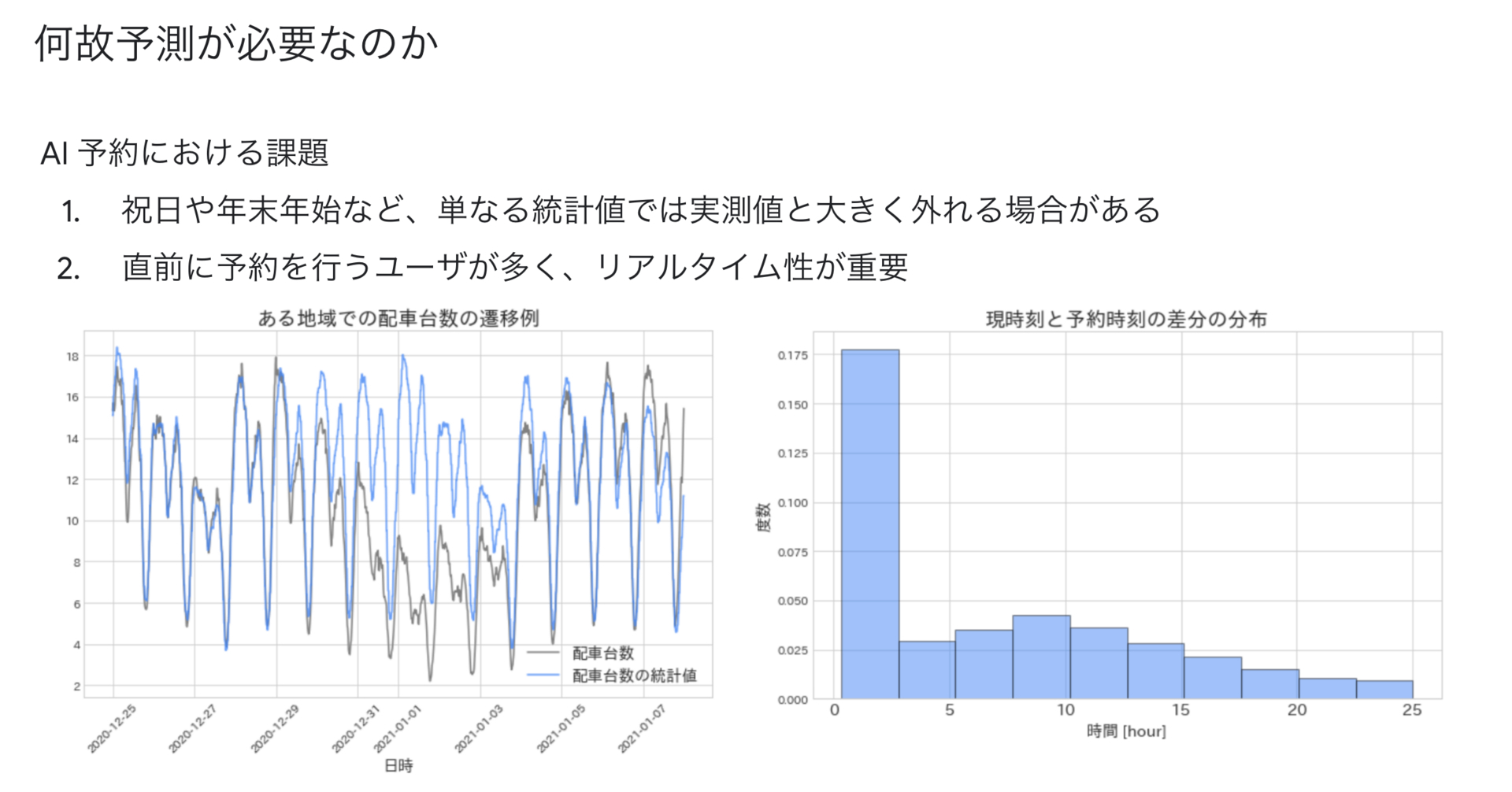
では、何故予測が必要となるのでしょうか? 機械学習モデルを構築する際は、コストがかかる場合がほとんどですので、それが本当に必要なのかを検証することが重要です。AI予約においては、祝日や年末年始・雨などで配車可能な車両台数がリアルタイムに移り変わります。また、予約するユーザは直前に予約することが多いということが分かっています。もし、ほとんどのユーザが1日後や2日後に予約するのであれば、機械学習モデルを用いてもそこまで精度が高くないことが多いので、予測せず曜日時間毎の統計値などを用いればいいかもしれません。しかし、実際には直前に予約を行うユーザが多いため、リアルタイムに予測することが重要だと考えられます。
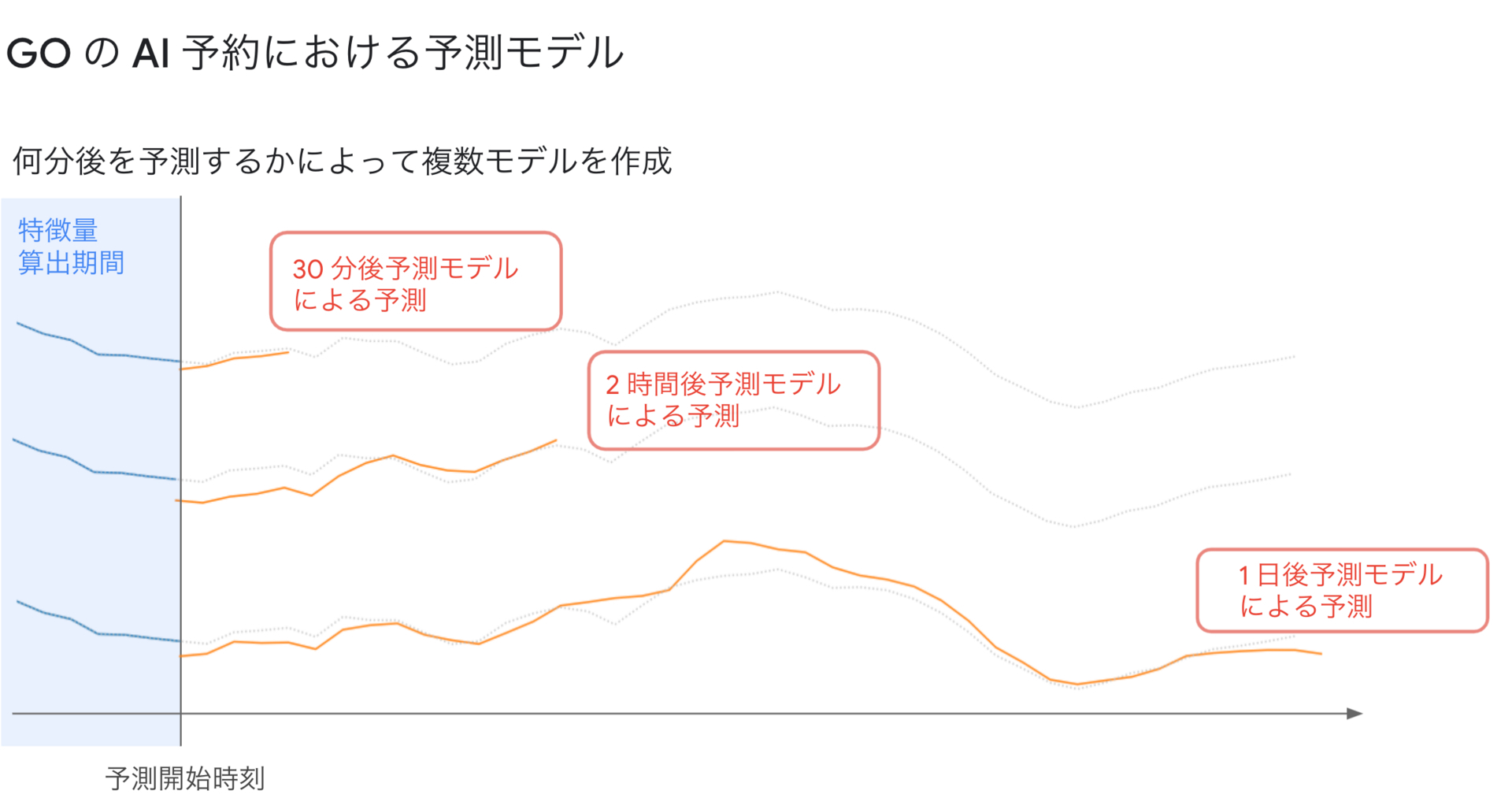
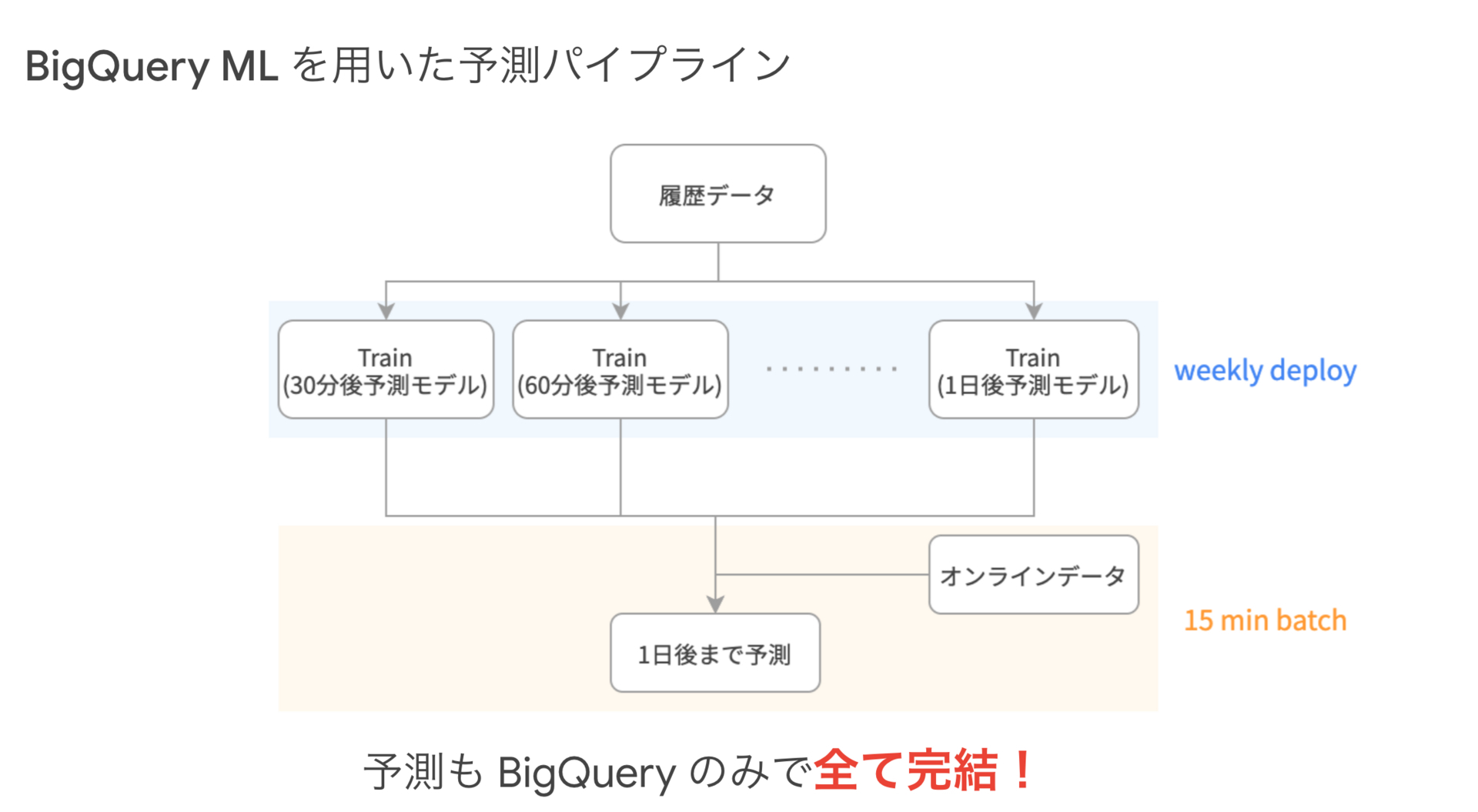
少し複雑になるのですが、どのような予測モデルを構築しているのかについても説明します。上で直前に予約するユーザが多いという話をしましたが、そのため現時刻直後の予測精度が重要となってきます。そのためなるべく直前の情報を用いて予測を行いたいのですが、1日後などを予測しようとする場合は、予測時に使える情報 (図の青い部分)と予測時刻が1日分離れてしまいます。ですので、1日後を予測するモデルと30分後を予測するモデルで同じものを使用してしまうと、30分後予測モデルでも1日前の情報しか用いることができず、直前の情報を利用できなくなってしまいます。そのため、AI予約では少しずつ間隔をあけて1日後を予測するモデルまでを別々に作成することで、直前特化のモデルや数時間後特化のモデルを作成しています。
他の方法としてNeural NetworkでSeq2Seqモデルを作成する方法や、ARIMAなどの自己回帰モデルを使用する方法などが考えられますが、実装の簡単さやモデルの精度の面から上の方法を選択しました。実際には、BigQuery ML の XGBoost モデルを採用しています。
上記のようなことをSQLで実現しようとすると複雑になりそうですが、これも上で紹介したJinja2 テンプレートを用いることで簡単に実装できます。次の図のクエリのようにN分後予測モデルに必要なパラメータを外出しすることで、SQLファイルとしては一つ作成しておくだけで済みます。実際に学習させる際には、N分後予測モデル毎にパラメータを渡したSQLをPythonで読み込み並列実行することで、簡単に並列学習を行うことができます。
また、スライドに書いていない追加のTIPSとして、統計値を取りたい期間のリストをパラメータとして渡し、forループを回すことで、平均を取る期間を変えた特徴量を簡単に記述できたりします。このように、特徴量をSQL上でたくさん作成したい場合にも Jinja2 テンプレートは便利です。

実際に、AI 予約で構築しているパイプラインの概略図は次のようになっています。週次で、N分後予測モデル毎に訓練を行い、15分毎にそれらのモデルの予測を結合することで1日後までの予測を行っています。定期実行の部分は、Cloud Composerという別サービスを用いていますが、一連の処理自体は BigQuery 上で全て完結しています。このように、BigQuery ML を用いれば AI 予約における複雑な予測においてもシンプルな構成で解決を行うことができます。
最後に、BigQuery ML を使用する際のいくつかの注意点や課題についても説明します。
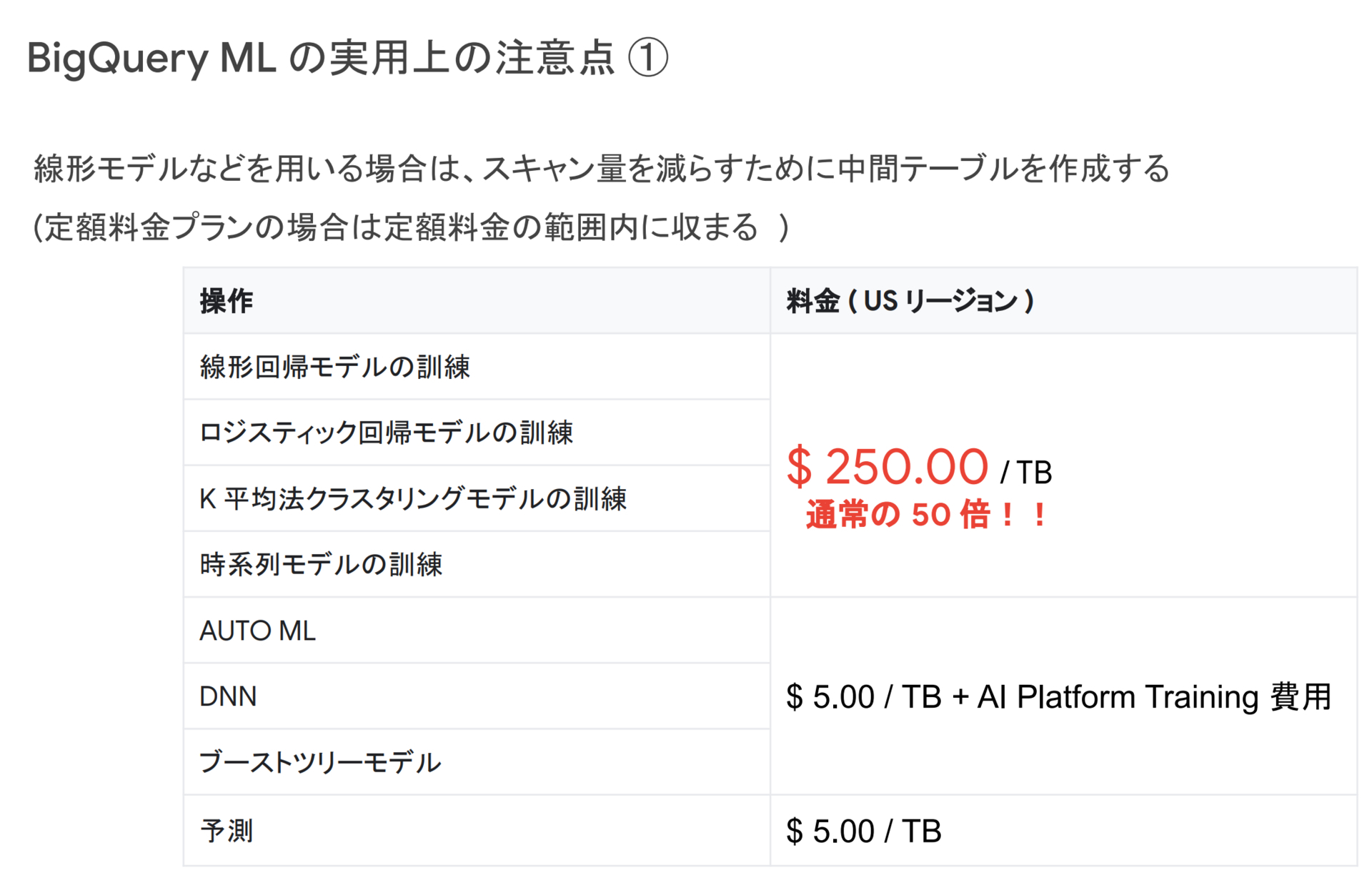
まず一つ目にコストについてです。定額料金プランを用いてる場合は問題になりませんが、スキャン量に対する値段が通常の50倍になります。そのため、線形モデルなどを用いる場合はBigQuery ML に投入する前に特徴量などを算出した中間テーブルを作成し、スキャン量を減らすといった工夫が必要となります。しかし、予測時には通常のスキャン量のみで済むので非常に良心的な値段設定ではないかと思います。
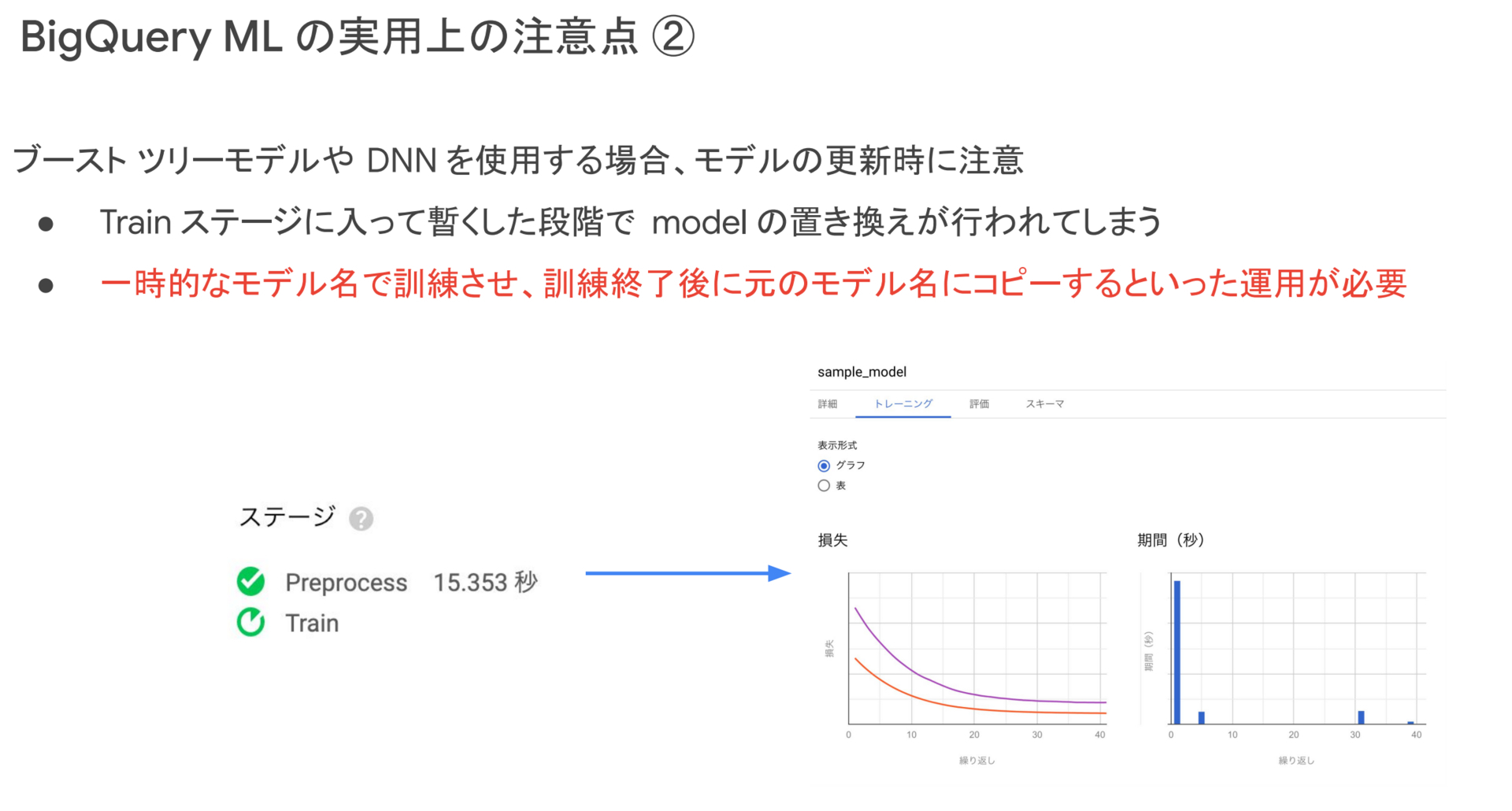
次に、モデルの更新についてです。これは、XGBoost や MLP などのモデルを訓練する際に注意することなのですが、SQLを実行し、例えば sample_model という model_id で学習を行ったとすると、SQLがTrainステージに入って暫くした段階で、データセット上の sample_model が置き換わってしまいます。例えば、週次で sample_model を更新するというようなことを行う際には、訓練を行っている少しの間は更新途中の sample_model を用いて予測を行うという事象が発生してしまい、精度劣化を引き起こす可能性があります。そのため、一時的なモデル名、例えばtmp_sample_model のような名前で訓練を行い、訓練が終了した後に sample_model にコピーを行うといった運用をする必要があります。
最後に実務で触っているうちに気づいたいくつかの課題について述べます。
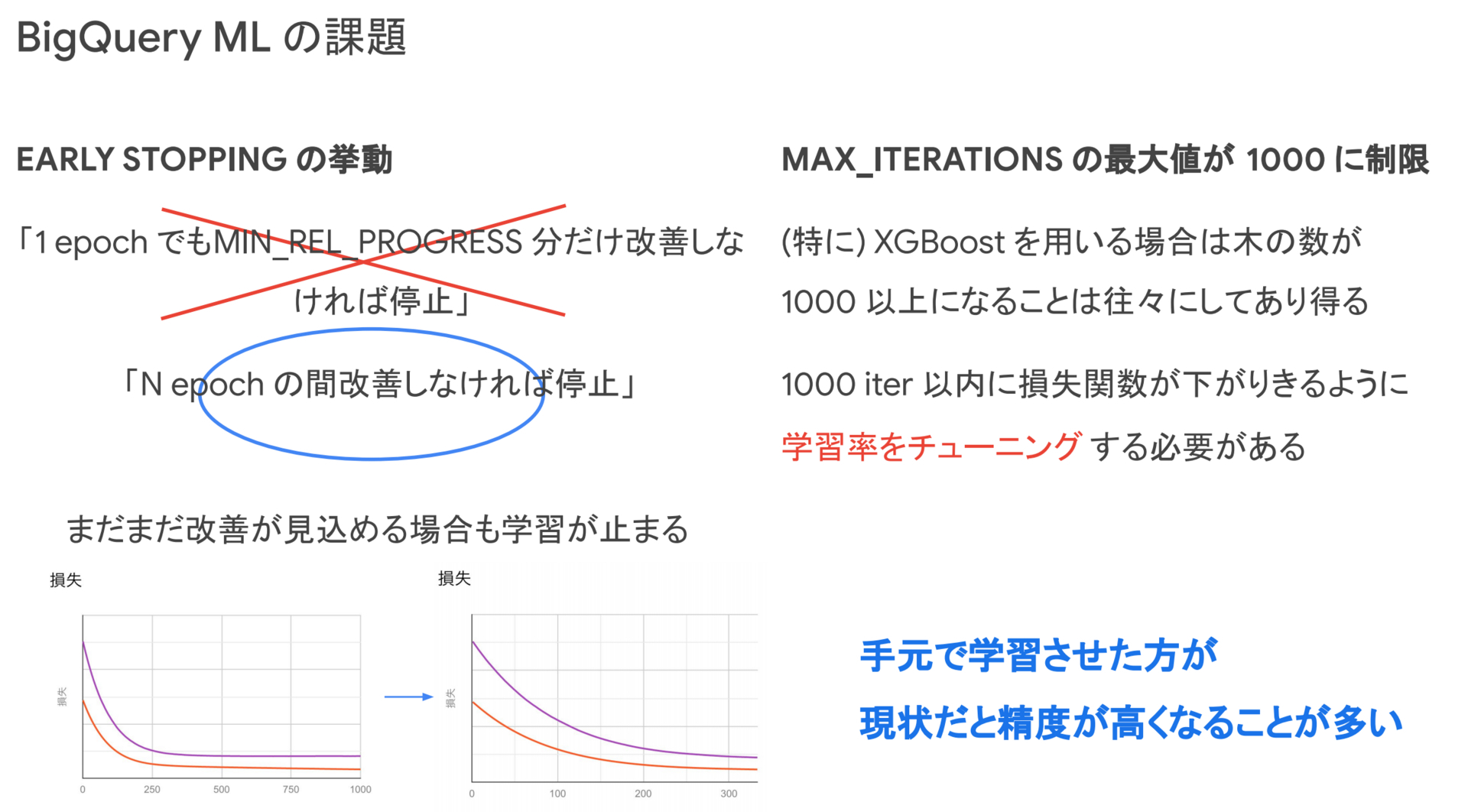
まず一つ目にEARLY_STOPPINGの挙動が扱いづらい点です。BQMLではMIN_REL_PROGRESS、というパラメータがあり、この値で設定した割合だけ検証データで損失が改善しなければ停止するといった挙動になります。しかし、普段、機械学習モデルを学習させたことのある方であれば経験があると思いますが、1 epochだけ改善しなくてもその後精度が改善するということは多くあります。そのため、現状のEARLY STOPPINGのアルゴリズムだと、スライドの左の図のように、まだまだ改善が見込める状況でもたった 1 epoch改善しないだけで学習が打ち切られてしまいます。ここは、多くの機械学習ライブラリに搭載されているようにN epochの間改善しなければ停止というアルゴリズムを取り入れていただきたいと感じています。
二つ目に学習のイテレーションの最大値が1000になっている点です。これは、予測を通常のスキャン量のみの値段で提供している手前仕方ないのかもしれません。しかし、XGBoostを用いる場合などは木の数が1000以上になるということは往々にしてありえます。この制限の中でちゃんと精度を出そうとすると、1000イテレーションの間に損失が下がりきるように、本来は行わないような学習率のチューニングといったことが必要となってしまいます。このチューニングのプロセスも BigQuery ML 上で全てやると高コストになってしまうため、チューニングのみ手元で行うといった作業が必要になり、BigQuery 上で全て完結するという本来の恩恵を受けることができなくなります。
このような大きくは二つの理由から、手元で学習させた方が現状だと少し精度が高くなるようなことが多いように感じられるので、この部分の改善は今後期待したいです。
おわりに
今回は、Google Cloud Day: Digital' 21 で老木と島越が登壇した内容について前半後半に分けて紹介しました。BigQuery や BigQuery ML の活用について、クエリ例や注意点・課題についても細かく紹介しているので、是非参考にしていただければと思います。