はじめに
はじめまして、AI技術開発部 分析グループの赤池です。
GO株式会社に入社して4ヶ月、これを機にPythonのデータハンドリングで長らくお世話になったpandasを卒業してPolarsに入学したのですが、 当初、やりたいことは明確なのにどう実装すればいいかわからず、ちょっとネットで調べても欲しい情報になかなか出会えず難儀しました。 そこで今回は自分が理解に難儀したポイントを中心に、「やりたいこと」を起点としたPolarsでの実装方法を整理します。 ライトな内容ですが、最後までお付き合いください。
なお、説明には基本的に以下のデータを使用します。 「2. 基本操作のおさらい」にてSQLと対比しながらPolarsの記法を説明しますが、 その際には以下のデータフレームと同名のテーブルが存在するものとしてSQLを書いています。
最後に、今回使用するPolarsのバージョンは「1.8.2」です。
import polars as pl from datetime import date log = pl.DataFrame( data=[ ["001", date(2023, 10, 1), "A", 4], ["001", date(2023, 11, 1), "B", 12], ["001", date(2023, 12, 31), "A", 3], ["001", date(2024, 3, 1), "B", 5], ["002", date(2024, 9, 1), "B", 2], ["002", date(2024, 10, 1), "B", 7], ["003", date(2023, 8, 1), "A", 1], ["003", date(2023, 10, 20), "A", 15], ["003", date(2023, 11, 1), "B", 5], ["003", date(2023, 11, 30), "B", 6], ], schema={ "ユーザーID": pl.String, "購入日": pl.Date, "商品ID": pl.String, "購入量": pl.Int32, }, orient="row" ) log # shape: (10, 4) # ┌────────────┬────────────┬────────┬────────┐ # │ ユーザーID ┆ 購入日 ┆ 商品ID ┆ 購入量 │ # │ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ date ┆ str ┆ i32 │ # ╞════════════╪════════════╪════════╪════════╡ # │ 001 ┆ 2023-10-01 ┆ A ┆ 4 │ # │ 001 ┆ 2023-11-01 ┆ B ┆ 12 │ # │ 001 ┆ 2023-12-31 ┆ A ┆ 3 │ # │ 001 ┆ 2024-03-01 ┆ B ┆ 5 │ # │ 002 ┆ 2024-09-01 ┆ B ┆ 2 │ # │ 002 ┆ 2024-10-01 ┆ B ┆ 7 │ # │ 003 ┆ 2023-08-01 ┆ A ┆ 1 │ # │ 003 ┆ 2023-10-20 ┆ A ┆ 15 │ # │ 003 ┆ 2023-11-01 ┆ B ┆ 5 │ # │ 003 ┆ 2023-11-30 ┆ B ┆ 6 │ # └────────────┴────────────┴────────┴────────┘ user = pl.DataFrame( data=[ ["001", "女性", date(2023, 10, 1), None], ["002", "男性", date(2024, 9, 1), None], ["003", "女性", date(2023, 8, 1), date(2023, 12, 1)], ], schema={ "ID": pl.String, "性別": pl.String, "登録日": pl.Date, "解約日": pl.Date, }, orient="row" ) user # shape: (3, 4) # ┌─────┬──────┬────────────┬────────────┐ # │ ID ┆ 性別 ┆ 登録日 ┆ 解約日 │ # │ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ str ┆ date ┆ date │ # ╞═════╪══════╪════════════╪════════════╡ # │ 001 ┆ 女性 ┆ 2023-10-01 ┆ null │ # │ 002 ┆ 男性 ┆ 2024-09-01 ┆ null │ # │ 003 ┆ 女性 ┆ 2023-08-01 ┆ 2023-12-01 │ # └─────┴──────┴────────────┴────────────┘ campaign = pl.DataFrame( data=[ ["001", "a"], ["001", "b"], ["003", "b"] ], schema={ "ユーザーID": pl.String, "キャンペーンID": pl.String, }, orient="row" ) campaign # shape: (3, 2) # ┌────────────┬────────────────┐ # │ ユーザーID ┆ キャンペーンID │ # │ --- ┆ --- │ # │ str ┆ str │ # ╞════════════╪════════════════╡ # │ 001 ┆ a │ # │ 001 ┆ b │ # │ 003 ┆ b │ # └────────────┴────────────────┘ store = pl.DataFrame( data=[ ["001", "A", 1_000_000, 1_500_000, 1.5], [None, "B", 500_000, 1_000_000, 2.0], ["002", "A", 1_000_000, 0, 0.0], [None, "B", 0, 1_000_000, float("inf")], ["003", "A", 0, 0, float("nan")], [None, "B", 2_000_000, 1_000_000, 0.5], [None, "C", None, None, None], ], schema={ "店舗ID": pl.Int32, "商品ID": pl.String, "売上_2023年": pl.Int64, "売上_2024年": pl.Int64, "売上前年比": pl.Float64, }, orient="row" ) store # shape: (7, 5) # ┌────────┬────────┬────────────┬───────────┬───────────┐ # │ 店舗ID ┆ 商品ID ┆ 売上_2023 ┆ 売上_2024 ┆ 売上前年 │ # │ --- ┆ --- ┆ 年 ┆ 年 ┆ 比 │ # │ i32 ┆ str ┆ --- ┆ --- ┆ --- │ # │ ┆ ┆ i64 ┆ i64 ┆ f64 │ # ╞════════╪════════╪════════════╪═══════════╪═══════════╡ # │ 1 ┆ A ┆ 1000000 ┆ 1500000 ┆ 1.5 │ # │ null ┆ B ┆ 500000 ┆ 1000000 ┆ 2.0 │ # │ 2 ┆ A ┆ 1000000 ┆ 0 ┆ 0.0 │ # │ null ┆ B ┆ 0 ┆ 1000000 ┆ inf │ # │ 3 ┆ A ┆ 0 ┆ 0 ┆ NaN │ # │ null ┆ B ┆ 2000000 ┆ 1000000 ┆ 0.5 │ # │ null ┆ C ┆ null ┆ null ┆ null │ # └────────┴────────┴────────────┴───────────┴───────────┘
目次
- カラムを選択したい
- 基本操作のおさらい
- 使い慣れた・知っている記法で処理を書きたい
- 他のデータに含まれないレコードを抽出したい
- 値が欠損しているカラムの出現レコード数を数えたい
- カラムの値をリストにしたい / リストを展開したい
- データフレームにグループごとに連番を振りたい
- 日付に対して任意の間隔の和や差を算出したい
- 時間の列を用いて、列をずらしたい
- 時間をずらして差分や増減率を算出したい
- 開始日から終了日までの日付を1日ごとに生成したい
- グループの先頭の値で欠損値を埋めたい
- 自作処理でメソッドチェーンしたい
1. カラムを選択したい
個人的に非常に初歩的にも関わらず混乱したこととして、カラムの選択方法が挙げられます。 当初ネットで情報を掻い摘んだ理解の浅い状態でPolarsを操作しており、「Polarsではpandasのようなカラム選択ができない」ものと思い込んでいました・・・が、実のところそれは間違った思い込みでした。
まず、私が想像している「pandasのようなカラム選択」とは、これです。
# Polars DataFrame → pandas DataFrame pd_user = user.to_pandas() # DataFrame pd_user[["ID", "性別"]] # ID 性別 # 0 001 女性 # 1 002 男性 # 2 003 女性 # Series pd_user["ID"] # 0 001 # 1 002 # 2 003 # Name: ID, dtype: object
そしてこれ、Polarsでもできます。
# DataFrame user[["ID", "性別"]] # shape: (3, 2) # ┌─────┬──────┐ # │ ID ┆ 性別 │ # │ --- ┆ --- │ # │ str ┆ str │ # ╞═════╪══════╡ # │ 001 ┆ 女性 │ # │ 002 ┆ 男性 │ # │ 003 ┆ 女性 │ # └─────┴──────┘ # Series user["ID"] # shape: (3,) # Series: 'ID' [str] # [ # "001" # "002" # "003" # ]
Polarsでカラムを選択するには、
user.select("ID", "性別")
や
user.select(pl.col("ID"), pl.col("性別"))
のように実装しないといけないものと勘違いしていましたが、pandasのように指定できました。 特に、カラムをSeriesとして取り出せることは実装の手数軽減に繋がりとても楽です。
# 購入量を合計する log.select(pl.col("購入量").sum()) # shape: (1, 1) # ┌────────┐ # │ 購入量 │ # │ --- │ # │ i32 │ # ╞════════╡ # │ 60 │ # └────────┘ # 上記をSeriesでやってみる log["購入量"].sum() # 60 # 性別ごとのユーザー数をカウントする user.select(pl.col("性別").value_counts(sort=True)).unnest("性別") # shape: (2, 2) # ┌──────┬───────┐ # │ 性別 ┆ count │ # │ --- ┆ --- │ # │ str ┆ u32 │ # ╞══════╪═══════╡ # │ 女性 ┆ 2 │ # │ 男性 ┆ 1 │ # └──────┴───────┘ # 上記をSeriesでやってみる user["性別"].value_counts(sort=True) # shape: (2, 2) # ┌──────┬───────┐ # │ 性別 ┆ count │ # │ --- ┆ --- │ # │ str ┆ u32 │ # ╞══════╪═══════╡ # │ 女性 ┆ 2 │ # │ 男性 ┆ 1 │ # └──────┴───────┘
しかし、このやり方はDataFrameではできるものの、LazyFrameではできません。
(LazyFrameに同様の処理を行うと、「Use select() or filter() instead.」 と怒られます)
リストや二重のリストでカラムを指定するやり方は実装効率がよいケースもありますが、DataFrameとLazyFrameの間で互換性がないことに注意が必要です。
2. 基本操作のおさらい
基本操作はPolarsの公式ドキュメントや他の方のブログなどにわかりやすくまとまっているのでそちらをご覧いただくのがよいと思いますが、こちらでも軽く紹介します。 なお、SQLはみなさんご存知だという前提で、各種処理を組み合わせた結果をSQLのクエリと比較しながら一気にまとめて触れます。
【SQL】
/* ## 要件 - 対象ユーザー : いずれかのキャンペーンに参加 - 対象商品 : 商品ID = 「B」 - 購入期間 : 2023年10月〜2024年3月 - 集計粒度 : 「ユーザーID」×月 - 集計対象 : 購入量 - 並び替え : 「ユーザーID」×月(昇順) */ WITH prep_user AS ( SELECT u.`ID` AS `ユーザーID` FROM user AS u INNER JOIN campaign AS c ON u.`ID` = c.`ユーザーID` ), prep_log AS ( SELECT *, EXTRACT(MONTH FROM `購入日`) AS `購入月` FROM log WHERE `商品ID` = 'B' AND `購入日` BETWEEN '2023-10-01' AND '2024-03-31' ) SELECT `ユーザーID`, `購入月`, SUM(`購入量`) AS `合計購入量` FROM prep_user AS u LEFT JOIN prep_log AS l USING (`ユーザーID`) GROUP BY `ユーザーID`, `購入月` ORDER BY `ユーザーID`, `購入月` ;
【Polars】
# 以下、上記クエリのWITH句に対応させて、Polarsで処理を記述 prep_user = ( user .join(campaign, left_on="ID", right_on="ユーザーID", how="inner") # `alias`で列名を変更(DataFrameやLazyFrameに`rename`をかけても実行可能) .select(pl.col("ID").alias("ユーザーID")) ) prep_log = ( log # SQLのWHERE句には`filter`が対応する .filter( 商品ID = 'B' # 単一の条件やAND条件の場合、カラムをExprやSeriesの形にしなくてもよい ) .filter( # SQLと異なり、DATE型のカラムを絞り込む場合は条件をDATE型に揃える必要がある pl.col("購入日").is_between( pl.lit('2023-10-01').cast(pl.Date), # SQL同様、castで変換 # pl.lit('2024-03-31').str.to_date(), # 文字列型なら`to_date`も使える date(2024, 3, 31) # Pythonのdate型で指定することもできる ) ) # カラムを追加する場合は`with_column`を使う .with_columns( # カラム名は`alias`を使わずに処理の前に書いても指定できる 購入月 = pl.col("購入日").dt.month() # `dt`アクセサで月を取り出せる ) # 上記処理は、次のように書いてもよい(カラムの絞り込みも同時に行う場合はこちらがより簡潔) # .select("ユーザーID", "購入日", "商品ID", "購入量", pl.col("購入日").dt.month().alias("購入月")) ) ( prep_user .join(prep_log, on="ユーザーID", how="left") .group_by("ユーザーID", "購入月") # ここではカラム名を列挙しているが、リストで指定することも可能 .agg( # 加工後のカラム名を指定しない場合、元のカラム名が踏襲される # 今回、加工後のカラム名が元のカラムに接頭辞をつけた形なので、 # 以下のように接頭辞を指定するだけでもよい pl.sum("購入量").name.prefix("合計") ) # SQLの`ORDER BY`には`sort`が対応する .sort("ユーザーID", "購入月") # `group_by`同様、リストで指定することも可能 ) # shape: (3, 3) # ┌────────────┬────────┬────────────┐ # │ ユーザーID ┆ 購入月 ┆ 合計購入量 │ # │ --- ┆ --- ┆ --- │ # │ str ┆ i8 ┆ i32 │ # ╞════════════╪════════╪════════════╡ # │ 001 ┆ 3 ┆ 10 │ # │ 001 ┆ 11 ┆ 24 │ # │ 003 ┆ 11 ┆ 11 │ # └────────────┴────────┴────────────┘
補足
DISTINCT
【SQL】
SELECT DISTINCT `ユーザーID`, `商品ID` FROM log;
【Polars】
SQLにおけるDISTINCTには、uniqueが対応します。
log.select('ユーザーID', '商品ID').unique() # shape: (5, 2) # ┌────────────┬────────┐ # │ ユーザーID ┆ 商品ID │ # │ --- ┆ --- │ # │ str ┆ str │ # ╞════════════╪════════╡ # │ 001 ┆ B │ # │ 003 ┆ B │ # │ 001 ┆ A │ # │ 003 ┆ A │ # │ 002 ┆ B │ # └────────────┴────────┘
型変換
カラムの型変換はcastで行えますが、カラムが文字列型の場合は以下のやり方もあります。
- 文字列 → 数値
col("{文字列型のカラム名}").str.to_integer()col("{文字列型のカラム名}").str.to_decimal()
- 文字列 → 日時
col("{文字列型のカラム名}").str.to_date()col("{文字列型のカラム名}").str.to_datetime()col("{文字列型のカラム名}").str.to_time()
# 例. String → Int64 log.with_columns(pl.col("ユーザーID").str.to_integer()) # shape: (10, 4) # ┌────────────┬────────────┬────────┬────────┐ # │ ユーザーID ┆ 購入日 ┆ 商品ID ┆ 購入量 │ # │ --- ┆ --- ┆ --- ┆ --- │ # │ i64 ┆ date ┆ str ┆ i32 │ # ╞════════════╪════════════╪════════╪════════╡ # │ 1 ┆ 2023-10-01 ┆ A ┆ 4 │ # │ 1 ┆ 2023-11-01 ┆ B ┆ 12 │ # │ 1 ┆ 2023-12-31 ┆ A ┆ 3 │ # │ 1 ┆ 2024-03-01 ┆ B ┆ 5 │ # │ 2 ┆ 2024-09-01 ┆ B ┆ 2 │ # │ 2 ┆ 2024-10-01 ┆ B ┆ 7 │ # │ 3 ┆ 2023-08-01 ┆ A ┆ 1 │ # │ 3 ┆ 2023-10-20 ┆ A ┆ 15 │ # │ 3 ┆ 2023-11-01 ┆ B ┆ 5 │ # │ 3 ┆ 2023-11-30 ┆ B ┆ 6 │ # └────────────┴────────────┴────────┴────────┘
BETWEENによる絞り込み
is_betweenではclosedオプションの引数を指定することで、抽出範囲を開区間、半開区間に切り替えることもできます。
こちらpandasでもできたそうなのですが、お恥ずかしながら今回Polarsを調べる中で初めて知りました・・・。
# 2023/10/1 < 登録日 <= 2024/10/1 で抽出 user.filter( pl.col("登録日").is_between( date(2023, 10, 1), date(2024, 10, 1), closed="right" ) ) # shape: (1, 4) # ┌─────┬──────┬────────────┬────────┐ # │ ID ┆ 性別 ┆ 登録日 ┆ 解約日 │ # │ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ str ┆ date ┆ date │ # ╞═════╪══════╪════════════╪════════╡ # │ 002 ┆ 男性 ┆ 2024-09-01 ┆ null │ # └─────┴──────┴────────────┴────────┘
3. 使い慣れた・知っている記法で処理を書きたい
例えば私のように使い慣れたpandasからPolarsに切り替える場合、初めのころはいちいち躓いて生産性が下がることを見越してPolarsを使うことになるかと思います。
to_pandasでPolarsのDataFrameをpandasのDataFrameに変換することで、実装方法がわからない箇所があってもpandasで処理できますが、処理で躓く度にデータ変換を行うのは手間がかかって辛いと思います。(少なくとも私ならそうです)
そんな私のような人に朗報が・・・なんとPolarsではsqlを使えばDataFrameやLazyFrameに対してSQLのクエリを実行できます。
例えば、上記「基本操作のおさらい」で用意したSQLは以下のようにそのまま実行できます。
query = """ /* ## 要件 - 対象ユーザー : いずれかのキャンペーンに参加 - 対象商品 : 商品ID = 「B」 - 購入期間 : 2023年10月〜2024年3月 - 集計粒度 : 「ユーザーID」×月 - 集計対象 : 購入量 - 並び替え : 「ユーザーID」×月(昇順) */ WITH prep_user AS ( SELECT u.`ID` AS `ユーザーID` FROM user AS u INNER JOIN campaign AS c ON u.`ID` = c.`ユーザーID` ), prep_log AS ( SELECT *, EXTRACT(MONTH FROM `購入日`) AS `購入月` FROM log WHERE `商品ID` = 'B' AND `購入日` BETWEEN '2023-10-01' AND '2024-03-31' ) SELECT `ユーザーID`, `購入月`, SUM(`購入量`) AS `合計購入量` FROM prep_user AS u LEFT JOIN prep_log AS l USING (`ユーザーID`) GROUP BY `ユーザーID`, `購入月` ORDER BY `ユーザーID`, `購入月` ; """ # `polars.sql`は結果がLazyFrameで返る pl.sql(query).collect() # shape: (3, 3) # ┌────────────┬────────┬────────────┐ # │ ユーザーID ┆ 購入月 ┆ 合計購入量 │ # │ --- ┆ --- ┆ --- │ # │ str ┆ i8 ┆ i32 │ # ╞════════════╪════════╪════════════╡ # │ 001 ┆ 3 ┆ 10 │ # │ 001 ┆ 11 ┆ 24 │ # │ 003 ┆ 11 ┆ 11 │ # └────────────┴────────┴────────────┘
ちなみにWINDOW関数も使用可能で、今回使用しているバージョン1.8.2においてはあまり不自由なくSQLを書けそうです。
query = """ SELECT *, SUM(`購入量`) OVER (PARTITION BY `ユーザーID`) AS `ユーザー別購入量` FROM self -- DataFrameやLazyFrameの`sql`メソッドを実行する場合、テーブル名は`self`とする ; """ # 返り値の型は、`sql`メソッドを持つデータの型と一致する # 下記ではDataFrameの`sql`メソッドを実行しているため、クエリの実行結果はDataFrameになる log.sql(query) # shape: (10, 5) # ┌────────────┬────────────┬────────┬────────┬──────────────────┐ # │ ユーザーID ┆ 購入日 ┆ 商品ID ┆ 購入量 ┆ ユーザー別購入量 │ # │ --- ┆ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ date ┆ str ┆ i32 ┆ i32 │ # ╞════════════╪════════════╪════════╪════════╪══════════════════╡ # │ 001 ┆ 2023-10-01 ┆ A ┆ 4 ┆ 24 │ # │ 001 ┆ 2023-11-01 ┆ B ┆ 12 ┆ 24 │ # │ 001 ┆ 2023-12-31 ┆ A ┆ 3 ┆ 24 │ # │ 001 ┆ 2024-03-01 ┆ B ┆ 5 ┆ 24 │ # │ 002 ┆ 2024-09-01 ┆ B ┆ 2 ┆ 9 │ # │ 002 ┆ 2024-10-01 ┆ B ┆ 7 ┆ 9 │ # │ 003 ┆ 2023-08-01 ┆ A ┆ 1 ┆ 27 │ # │ 003 ┆ 2023-10-20 ┆ A ┆ 15 ┆ 27 │ # │ 003 ┆ 2023-11-01 ┆ B ┆ 5 ┆ 27 │ # │ 003 ┆ 2023-11-30 ┆ B ┆ 6 ┆ 27 │ # └────────────┴────────────┴────────┴────────┴──────────────────┘
さらに、sql_exprでSQLの関数を借用することもできます。
次の例は、上記のWINDOW関数でカラム追加する処理を書き換えたものです。
log.with_columns(pl.sql_expr("SUM(`購入量`) OVER (PARTITION BY `ユーザーID`) AS `ユーザー別購入量`"))
そして、参照できるデータはPolarsで作成されたものだけかと思いきや、なんとpandasのDataFrameやPyArrow Tableなども参照できます。(参照) こうなってくると、慣れているツールで「部品」を作っておいて、それをPolarsと組み合わせて処理することもできそうです。
import pandas as pd pd_df = pd.DataFrame({ "index": [1, 2, 3], "val": [5, 15, 20], }) pl_df = pl.DataFrame({ "index": [1, 2, 3], "val": ["A", "B", "C"], }) pl_lf = pl.LazyFrame({ "index": [1, 2, 3], "val": ["001", "002", "003"], }) pl.sql(""" SELECT index, pd_df.val AS pd_df_val, pl_df.val AS pl_df_val, pl_lf.val AS pl_lf_val FROM pd_df LEFT JOIN pl_df USING (index) LEFT JOIN pl_lf USING (index) ; """).collect() # shape: (3, 4) # ┌───────┬───────────┬───────────┬───────────┐ # │ index ┆ pd_df_val ┆ pl_df_val ┆ pl_lf_val │ # │ --- ┆ --- ┆ --- ┆ --- │ # │ i64 ┆ i64 ┆ str ┆ str │ # ╞═══════╪═══════════╪═══════════╪═══════════╡ # │ 1 ┆ 5 ┆ A ┆ 001 │ # │ 2 ┆ 15 ┆ B ┆ 002 │ # │ 3 ┆ 20 ┆ C ┆ 003 │ # └───────┴───────────┴───────────┴───────────┘
4. 他のデータに含まれないレコードを抽出したい
例えば、「新たな販促キャンペーンを、過去に一度もキャンペーンに参加したことのないユーザーに実施したい」とします。 この時、ユーザーマスタと過去の販促キャンペーン参加を管理しているテーブルがあれば、以下のようにテーブル結合してから絞り込むことで抽出できます。
SELECT * FROM user AS u LEFT JOIN campaign AS c ON u.`ID` = c.`ユーザーID` WHERE c.`ユーザーID` IS NULL ;
SQLだとこのように「テーブル結合 → 絞り込み」の2ステップが必要ですが、Polarsでは「anti join」を使えばテーブル結合だけでシンプルに実装できます。 なおこれは、結合キーに対応するレコードが左側(結合される側)のテーブルだけにあって右側(結合する側)のテーブルにないものを出力する処理です。
user.join(campaign, left_on="ID", right_on="ユーザーID", how="anti") # shape: (1, 4) # ┌─────┬──────┬────────────┬────────┐ # │ ID ┆ 性別 ┆ 登録日 ┆ 解約日 │ # │ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ str ┆ date ┆ date │ # ╞═════╪══════╪════════════╪════════╡ # │ 002 ┆ 男性 ┆ 2024-09-01 ┆ null │ # └─────┴──────┴────────────┴────────┘
5. 値が欠損しているカラムの出現レコード数を数えたい
storeの「売上前年比」カラムにはNaNとNullが1レコードずつ含まれますが、このカラムのNullの件数をカウントすると以下のようになります。
store.select(pl.col("売上前年比").null_count()) # shape: (1, 1) # ┌────────────┐ # │ 売上前年比 │ # │ --- │ # │ u32 │ # ╞════════════╡ # │ 1 │ # └────────────┘
この結果はpandasやSQLで実行した場合とは異なります。
例えば、pandasではisnullとisnaのいずれもNaNをTrueと判定するため、その感覚で考えると上記の結果は「2」になります。
そして、そもそもstoreの「売上前年比」カラムにおけるNaNは0を0で割ることで発生していますが、これをSQLでsafe_divideを使って計算するとNullになります。
そのため売上前年比の計算からNullのレコード数のカウントまでをSQLで実行した場合、結果はpandasと同様に「2」になります。
PolarsではNullとNaNを別物として扱うため、両者に対応するメソッドは相互に互換性がありません。
そのため上記処理のnull_countはあくまでもNullの件数のみカウントし、NaNは無視しています。
なお「一発でNaNをカウントするメソッド」はないため、意図せぬNaNがデータに含まれているかを確認するためには例えばis_nanの判定結果を数えるなどの対応が必要になります。
(
store
.select(pl.col("売上前年比").is_nan().value_counts(sort=True))
.unnest("売上前年比") # そのままだとStruct型なので変換(好みの問題)
)
# shape: (3, 2)
# ┌────────────┬───────┐
# │ 売上前年比 ┆ count │
# │ --- ┆ --- │
# │ bool ┆ u32 │
# ╞════════════╪═══════╡
# │ false ┆ 5 │
# │ true ┆ 1 │
# │ null ┆ 1 │
# └────────────┴───────┘
# データがDataFrameの場合のみ(DataFrameからカラムをSeriesで取り出し、判定)
store["売上前年比"].is_nan().value_counts(sort=True)
# shape: (3, 2)
# ┌────────────┬───────┐
# │ 売上前年比 ┆ count │
# │ --- ┆ --- │
# │ bool ┆ u32 │
# ╞════════════╪═══════╡
# │ false ┆ 5 │
# │ true ┆ 1 │
# │ null ┆ 1 │
# └────────────┴───────┘
NaNもNullとして合わせてカウントしたい場合は、例えば以下のようにNaNをNullに置換してからnull_countでレコード数を計算する(パターン1)、filterで判定してレコード数を計算する(パターン2)、の2つのパターンが考えられます。
# パターン1: NaNをNullに置換してから、Nullの数をカウント ( store .with_columns(pl.col("売上前年比").fill_nan(None)) .select(pl.col("売上前年比").null_count()) ) # shape: (1, 1) # ┌────────────┐ # │ 売上前年比 │ # │ --- │ # │ u32 │ # ╞════════════╡ # │ 2 │ # └────────────┘ # パターン2: NaNとNullのみに絞ってからレコード数をカウント store.filter( (pl.col("売上前年比").is_null()) | (pl.col("売上前年比").is_nan()) ).shape[0] # 2
少々話が脇道に逸れますが、集計対象のカラムにNaNやNullが混在する場合もそれぞれ挙動が異なります。ここではcount、sum、meanを例として見てみます。
NaNはあくまでも欠損ではなく値として扱われるのに対してNullは欠損なので、以下のようになります。
データハンドリングの過程でNaNが生じた場合、それに意識せず集計してしまうと思わぬ結果となってしまうことに注意が必要です。
# データの準備 df = pl.DataFrame( data=[["Nullを含む", None], ["Nullを含む", 1], ["Nullを含む", 2], ["NaNを含む", float("nan")], ["NaNを含む", 1], ["NaNを含む", 2]], schema={ "index": pl.String, "val": pl.Float64, } ) # shape: (6, 2) # ┌────────────┬──────┐ # │ index ┆ val │ # │ --- ┆ --- │ # │ str ┆ f64 │ # ╞════════════╪══════╡ # │ Nullを含む ┆ null │ # │ Nullを含む ┆ 1.0 │ # │ Nullを含む ┆ 2.0 │ # │ NaNを含む ┆ NaN │ # │ NaNを含む ┆ 1.0 │ # │ NaNを含む ┆ 2.0 │ # └────────────┴──────┘ # 集計実行 ( df .group_by("index") .agg( pl.count("val").alias("count"), pl.sum("val").alias("sum"), pl.mean("val").alias("mean"), ) .transpose(include_header=True, column_names="index") ) # shape: (3, 3) # ┌────────┬────────────┬───────────┐ # │ column ┆ Nullを含む ┆ NaNを含む │ # │ --- ┆ --- ┆ --- │ # │ str ┆ f64 ┆ f64 │ # ╞════════╪════════════╪═══════════╡ # │ count ┆ 2.0 ┆ 3.0 │ # │ sum ┆ 3.0 ┆ NaN │ # │ mean ┆ 1.5 ┆ NaN │ # └────────┴────────────┴───────────┘
6. カラムの値をリストにしたい / リストを展開したい
リストにしたい あるカラムの値の組み合わせに対応する複数の値をリストにまとめたい場合は、Polarsでは以下のように実装します。
campaign_agg = (
campaign
.group_by("ユーザーID")
.agg(pl.col("キャンペーンID").alias("キャンペーンID_list"))
)
campaign_agg
# shape: (2, 2)
# ┌────────────┬─────────────────────┐
# │ ユーザーID ┆ キャンペーンID_list │
# │ --- ┆ --- │
# │ str ┆ list[str] │
# ╞════════════╪═════════════════════╡
# │ 001 ┆ ["a", "b"] │
# │ 003 ┆ ["b"] │
# └────────────┴─────────────────────┘
GROUP BYしてから、対象のカラムについて集計関数などをかけなければリストに変換できます。
なお、この例のようにgroup_byをかけた場合にimplodeを繋げると二重のリストになってしまうため注意が必要です。
(
campaign
.group_by("ユーザーID")
.agg(pl.col("キャンペーンID").implode().alias("キャンペーンID_list"))
)
# shape: (2, 2)
# ┌────────────┬─────────────────────┐
# │ ユーザーID ┆ キャンペーンID_list │
# │ --- ┆ --- │
# │ str ┆ list[list[str]] │
# ╞════════════╪═════════════════════╡
# │ 001 ┆ [["a", "b"]] │
# │ 003 ┆ [["b"]] │
# └────────────┴─────────────────────┘
リストを展開したい
リストを展開するときはexplodeを使います。
campaign_agg.explode("キャンペーンID_list") # shape: (3, 2) # ┌────────────┬─────────────────────┐ # │ ユーザーID ┆ キャンペーンID_list │ # │ --- ┆ --- │ # │ str ┆ str │ # ╞════════════╪═════════════════════╡ # │ 001 ┆ a │ # │ 001 ┆ b │ # │ 003 ┆ b │ # └────────────┴─────────────────────┘
7. データフレームにグループごとに連番を振りたい
例えば、あるグループごとにイベントの発生順序を振りたいとします。 その場合、Polarsでは以下のように実装できます。
# ユーザーごとに購入順を振る ( log .with_columns( # カウント用の値を用意 pl.lit(1).alias("購入順") ) .with_columns( pl.cum_count("購入順").over(partition_by="ユーザーID", order_by="購入日") ) ) # shape: (10, 5) # ┌────────────┬────────────┬────────┬────────┬────────┐ # │ ユーザーID ┆ 購入日 ┆ 商品ID ┆ 購入量 ┆ 購入順 │ # │ --- ┆ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ date ┆ str ┆ i32 ┆ u32 │ # ╞════════════╪════════════╪════════╪════════╪════════╡ # │ 001 ┆ 2023-10-01 ┆ A ┆ 4 ┆ 1 │ # │ 001 ┆ 2023-11-01 ┆ B ┆ 12 ┆ 2 │ # │ 001 ┆ 2023-12-31 ┆ A ┆ 3 ┆ 3 │ # │ 001 ┆ 2024-03-01 ┆ B ┆ 5 ┆ 4 │ # │ 002 ┆ 2024-09-01 ┆ B ┆ 2 ┆ 1 │ # │ 002 ┆ 2024-10-01 ┆ B ┆ 7 ┆ 2 │ # │ 003 ┆ 2023-08-01 ┆ A ┆ 1 ┆ 1 │ # │ 003 ┆ 2023-10-20 ┆ A ┆ 15 ┆ 2 │ # │ 003 ┆ 2023-11-01 ┆ B ┆ 5 ┆ 3 │ # │ 003 ┆ 2023-11-30 ┆ B ┆ 6 ┆ 4 │ # └────────────┴────────────┴────────┴────────┴────────┘
8. 日付に対して任意の間隔の和や差を算出したい
SQLのdate_add関数やdate_sub関数のように「ある日付から○日前・後」の日付を取得したい場合、Polarsでは以下のようにoffset_byを使って実装します。
# 1日前 user.with_columns(pl.col("登録日").dt.offset_by("-1d").alias("登録日_1日前")) # shape: (3, 5) # ┌─────┬──────┬────────────┬────────────┬──────────────┐ # │ ID ┆ 性別 ┆ 登録日 ┆ 解約日 ┆ 登録日_1日前 │ # │ --- ┆ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ str ┆ date ┆ date ┆ date │ # ╞═════╪══════╪════════════╪════════════╪══════════════╡ # │ 001 ┆ 女性 ┆ 2023-10-01 ┆ null ┆ 2023-09-30 │ # │ 002 ┆ 男性 ┆ 2024-09-01 ┆ null ┆ 2024-08-31 │ # │ 003 ┆ 女性 ┆ 2023-08-01 ┆ 2023-12-01 ┆ 2023-07-31 │ # └─────┴──────┴────────────┴────────────┴──────────────┘ # 1ヶ月後 user.with_columns(pl.col("登録日").dt.offset_by("1mo").alias("登録日_1ヶ月後")) # shape: (3, 5) # ┌─────┬──────┬────────────┬────────────┬────────────────┐ # │ ID ┆ 性別 ┆ 登録日 ┆ 解約日 ┆ 登録日_1ヶ月後 │ # │ --- ┆ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ str ┆ date ┆ date ┆ date │ # ╞═════╪══════╪════════════╪════════════╪════════════════╡ # │ 001 ┆ 女性 ┆ 2023-10-01 ┆ null ┆ 2023-11-01 │ # │ 002 ┆ 男性 ┆ 2024-09-01 ┆ null ┆ 2024-10-01 │ # │ 003 ┆ 女性 ┆ 2023-08-01 ┆ 2023-12-01 ┆ 2023-09-01 │ # └─────┴──────┴────────────┴────────────┴────────────────┘
9. 時間の列を用いて、列をずらしたい
例えば日ごとの値を時点間で比較 & 加工した値(差分、増減率など)を求めたい場合、まずは時点をずらしたカラムを作ることが思い浮かぶのではないでしょうか?(私はそうでした)
そういった、SQLでいうところの LAG({ずらすカラム}, 1) OVER (PARTITION BY {グループのキー} ORDER BY {時間のカラム}) は、Polarsでは以下のように実装できます。
# 「ユーザーID」「商品ID」ごとに、**1つ前**の購入タイミングの購入量のカラムを追加 log.with_columns( pl.col("購入量") .shift(1) .over(partition_by=["ユーザーID", "商品ID"], order_by="購入日") .alias("前回購入量") ) # shape: (10, 5) # ┌────────────┬────────────┬────────┬────────┬────────────┐ # │ ユーザーID ┆ 購入日 ┆ 商品ID ┆ 購入量 ┆ 前回購入量 │ # │ --- ┆ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ date ┆ str ┆ i32 ┆ i32 │ # ╞════════════╪════════════╪════════╪════════╪════════════╡ # │ 001 ┆ 2023-10-01 ┆ A ┆ 4 ┆ null │ # │ 001 ┆ 2023-11-01 ┆ B ┆ 12 ┆ null │ # │ 001 ┆ 2023-12-31 ┆ A ┆ 3 ┆ 4 │ # │ 001 ┆ 2024-03-01 ┆ B ┆ 5 ┆ 12 │ # │ 002 ┆ 2024-09-01 ┆ B ┆ 2 ┆ null │ # │ 002 ┆ 2024-10-01 ┆ B ┆ 7 ┆ 2 │ # │ 003 ┆ 2023-08-01 ┆ A ┆ 1 ┆ null │ # │ 003 ┆ 2023-10-20 ┆ A ┆ 15 ┆ 1 │ # │ 003 ┆ 2023-11-01 ┆ B ┆ 5 ┆ null │ # │ 003 ┆ 2023-11-30 ┆ B ┆ 6 ┆ 5 │ # └────────────┴────────────┴────────┴────────┴────────────┘ # 「ユーザーID」「商品ID」ごとに、**1つ後**の購入タイミングの購入量のカラムを追加 log.with_columns( pl.col("購入量") .shift(-1) .over(partition_by=["ユーザーID", "商品ID"], order_by="購入日") .alias("次回購入量") ) # shape: (10, 5) # ┌────────────┬────────────┬────────┬────────┬────────────┐ # │ ユーザーID ┆ 購入日 ┆ 商品ID ┆ 購入量 ┆ 次回購入量 │ # │ --- ┆ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ date ┆ str ┆ i32 ┆ i32 │ # ╞════════════╪════════════╪════════╪════════╪════════════╡ # │ 001 ┆ 2023-10-01 ┆ A ┆ 4 ┆ 3 │ # │ 001 ┆ 2023-11-01 ┆ B ┆ 12 ┆ 5 │ # │ 001 ┆ 2023-12-31 ┆ A ┆ 3 ┆ null │ # │ 001 ┆ 2024-03-01 ┆ B ┆ 5 ┆ null │ # │ 002 ┆ 2024-09-01 ┆ B ┆ 2 ┆ 7 │ # │ 002 ┆ 2024-10-01 ┆ B ┆ 7 ┆ null │ # │ 003 ┆ 2023-08-01 ┆ A ┆ 1 ┆ 15 │ # │ 003 ┆ 2023-10-20 ┆ A ┆ 15 ┆ null │ # │ 003 ┆ 2023-11-01 ┆ B ┆ 5 ┆ 6 │ # │ 003 ┆ 2023-11-30 ┆ B ┆ 6 ┆ null │ # └────────────┴────────────┴────────┴────────┴────────────┘
10. 時間をずらして差分や増減率を算出したい
9では、例えばある値の前日からの差分や増減率を算出する場合、まずはそのカラムを時間でずらしたカラムを作成することを考えました。 しかしPolarsではそんなワンクッションを挟まずとも、以下の方法で一気に差分や増減率を算出できます。
log.with_columns(
pl.col("購入量").shift(1).over(partition_by=["ユーザーID", "商品ID"], order_by="購入日").alias("(確認用)前回購入量"),
pl.col("購入量").diff(1).over(partition_by=["ユーザーID", "商品ID"], order_by="購入日").alias("購入量差分"),
pl.col("購入量").pct_change(1).over(partition_by=["ユーザーID", "商品ID"], order_by="購入日").alias("購入量増減率"),
)
# shape: (10, 7)
# ┌────────────┬────────────┬────────┬────────┬──────────────────────┬────────────┬──────────────┐
# │ ユーザーID ┆ 購入日 ┆ 商品ID ┆ 購入量 ┆ (確認用)前回購入量 ┆ 購入量差分 ┆ 購入量増減率 │
# │ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │
# │ str ┆ date ┆ str ┆ i32 ┆ i32 ┆ i32 ┆ f64 │
# ╞════════════╪════════════╪════════╪════════╪══════════════════════╪════════════╪══════════════╡
# │ 001 ┆ 2023-10-01 ┆ A ┆ 4 ┆ null ┆ null ┆ null │
# │ 001 ┆ 2023-11-01 ┆ B ┆ 12 ┆ null ┆ null ┆ null │
# │ 001 ┆ 2023-12-31 ┆ A ┆ 3 ┆ 4 ┆ -1 ┆ -0.25 │
# │ 001 ┆ 2024-03-01 ┆ B ┆ 5 ┆ 12 ┆ -7 ┆ -0.583333 │
# │ 002 ┆ 2024-09-01 ┆ B ┆ 2 ┆ null ┆ null ┆ null │
# │ 002 ┆ 2024-10-01 ┆ B ┆ 7 ┆ 2 ┆ 5 ┆ 2.5 │
# │ 003 ┆ 2023-08-01 ┆ A ┆ 1 ┆ null ┆ null ┆ null │
# │ 003 ┆ 2023-10-20 ┆ A ┆ 15 ┆ 1 ┆ 14 ┆ 14.0 │
# │ 003 ┆ 2023-11-01 ┆ B ┆ 5 ┆ null ┆ null ┆ null │
# │ 003 ┆ 2023-11-30 ┆ B ┆ 6 ┆ 5 ┆ 1 ┆ 0.2 │
# └────────────┴────────────┴────────┴────────┴──────────────────────┴────────────┴──────────────┘
11. 開始日から終了日までの日付を1日ごとに生成したい
例えば、「ユーザー×日」の粒度で管理されているデータに対して日次の増減率を算出したいとします。 この時、日に欠損がなければ前出のやり方で対応できますが、欠損している場合はあらかじめ埋める必要があり、Polarsでは以下のように実装できます。
# ユーザーごとに、「登録日」から「終了日」までの1日ごとの日付を生成する ( user .with_columns(pl.lit("2024-10-31").str.to_date().alias("最終日")) .group_by("ID", "性別") .agg( # 「登録日」から「終了日」までの日付を1日ごとに**リスト型で**生成 pl.date_range("登録日", "最終日", "1d").alias("日") ) # リスト型の日付カラムを展開 .explode("日") ) # shape: (916, 3) # ┌─────┬──────┬────────────┐ # │ ID ┆ 性別 ┆ 日 │ # │ --- ┆ --- ┆ --- │ # │ str ┆ str ┆ date │ # ╞═════╪══════╪════════════╡ # │ 003 ┆ 女性 ┆ 2023-08-01 │ # │ 003 ┆ 女性 ┆ 2023-08-02 │ # │ 003 ┆ 女性 ┆ 2023-08-03 │ # │ 003 ┆ 女性 ┆ 2023-08-04 │ # │ 003 ┆ 女性 ┆ 2023-08-05 │ # │ … ┆ … ┆ … │ # │ 001 ┆ 女性 ┆ 2024-10-27 │ # │ 001 ┆ 女性 ┆ 2024-10-28 │ # │ 001 ┆ 女性 ┆ 2024-10-29 │ # │ 001 ┆ 女性 ┆ 2024-10-30 │ # │ 001 ┆ 女性 ┆ 2024-10-31 │ # └─────┴──────┴────────────┘
12. グループの先頭の値で欠損値を埋めたい
突然ですが、皆様は集計キーなどのカラムの先頭だけに値が入っていたり、セル結合されたExcelの表を見たことはありますでしょうか?
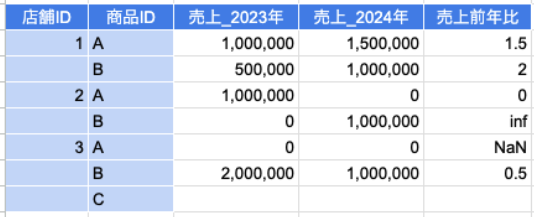
こういった表をPythonで読み込んで使用するには欠損箇所を埋める必要がありますが、Polarsだとforward_fillで簡単に処理できます。
store.with_columns(pl.col("店舗ID").forward_fill()) # shape: (7, 5) # ┌────────┬────────┬─────────────┬─────────────┬────────────┐ # │ 店舗ID ┆ 商品ID ┆ 売上_2023年 ┆ 売上_2024年 ┆ 売上前年比 │ # │ --- ┆ --- ┆ --- ┆ --- ┆ --- │ # │ i32 ┆ str ┆ i64 ┆ i64 ┆ f64 │ # ╞════════╪════════╪═════════════╪═════════════╪════════════╡ # │ 1 ┆ A ┆ 1000000 ┆ 1500000 ┆ 1.5 │ # │ 1 ┆ B ┆ 500000 ┆ 1000000 ┆ 2.0 │ # │ 2 ┆ A ┆ 1000000 ┆ 0 ┆ 0.0 │ # │ 2 ┆ B ┆ 0 ┆ 1000000 ┆ inf │ # │ 3 ┆ A ┆ 0 ┆ 0 ┆ NaN │ # │ 3 ┆ B ┆ 2000000 ┆ 1000000 ┆ 0.5 │ # │ 3 ┆ C ┆ null ┆ null ┆ null │ # └────────┴────────┴─────────────┴─────────────┴────────────┘ # `fill_null`でも可 store.with_columns(pl.col("店舗ID").fill_null(strategy="forward")) # shape: (7, 5) # ┌────────┬────────┬─────────────┬─────────────┬────────────┐ # │ 店舗ID ┆ 商品ID ┆ 売上_2023年 ┆ 売上_2024年 ┆ 売上前年比 │ # │ --- ┆ --- ┆ --- ┆ --- ┆ --- │ # │ i32 ┆ str ┆ i64 ┆ i64 ┆ f64 │ # ╞════════╪════════╪═════════════╪═════════════╪════════════╡ # │ 1 ┆ A ┆ 1000000 ┆ 1500000 ┆ 1.5 │ # │ 1 ┆ B ┆ 500000 ┆ 1000000 ┆ 2.0 │ # │ 2 ┆ A ┆ 1000000 ┆ 0 ┆ 0.0 │ # │ 2 ┆ B ┆ 0 ┆ 1000000 ┆ inf │ # │ 3 ┆ A ┆ 0 ┆ 0 ┆ NaN │ # │ 3 ┆ B ┆ 2000000 ┆ 1000000 ┆ 0.5 │ # │ 3 ┆ C ┆ null ┆ null ┆ null │ # └────────┴────────┴─────────────┴─────────────┴────────────┘
13. 自作処理でメソッドチェーンしたい
個人的な話で恐縮ですが、これまで「都度の実装を楽にするために、あらかじめよく使う処理をまとめておきたいんだよな・・・。それも、関数の引数にDataFrameを与えるとか、mapで適用するとかそういうことじゃなく、メソッドチェーンの流れで処理を適用したいんだよな・・・。」なんて思っていました。 そこで調べてみると、割と簡単に実現できることがわかりました(参照)。
ここでは試しに、DataFrameの簡易バリデーション処理を作ってみます。
# data_check.py import polars as pl import polars.selectors as cs @pl.api.register_dataframe_namespace("chk") class DataCheck: def __init__(self, df: pl.DataFrame) -> None: self._df = df def valid(self) -> None: cols = self._df.columns print("【テーブル】") print("- レコード数:", self._df.shape[0]) print("- ユニーク数:", self._df.unique().shape[0]) print() df_n_unique = ( self._df .select(cs.all().n_unique()) .with_columns(pl.lit("ユニーク数").alias("column")) ) df_null = ( self._df .null_count() .with_columns(pl.lit("Nullのレコード数").alias("column")) ) df_nan = ( self._df .select(cs.numeric().is_nan().sum()) .with_columns(pl.lit("NaNのレコード数").alias("column")) ) print("【カラム】") print( pl.concat([df_n_unique, df_null, df_nan], how="diagonal") .fill_null(0) .select(["column"] + cols) )
# 実行 import data_check store.chk.valid() # 【テーブル】 # - レコード数: 7 # - ユニーク数: 7 # 【カラム】 # shape: (3, 6) # ┌──────────────────┬────────┬────────┬─────────────┬─────────────┬────────────┐ # │ column ┆ 店舗ID ┆ 商品ID ┆ 売上_2023年 ┆ 売上_2024年 ┆ 売上前年比 │ # │ --- ┆ --- ┆ --- ┆ --- ┆ --- ┆ --- │ # │ str ┆ u32 ┆ u32 ┆ u32 ┆ u32 ┆ u32 │ # ╞══════════════════╪════════╪════════╪═════════════╪═════════════╪════════════╡ # │ ユニーク数 ┆ 4 ┆ 3 ┆ 5 ┆ 4 ┆ 7 │ # │ Nullのレコード数 ┆ 4 ┆ 0 ┆ 1 ┆ 1 ┆ 1 │ # │ NaNのレコード数 ┆ 0 ┆ 0 ┆ 0 ┆ 0 ┆ 1 │ # └──────────────────┴────────┴────────┴─────────────┴─────────────┴────────────┘
おわりに
今回はPolarsを使ったデータハンドリングにて私が躓いたポイントを中心にまとめました。 Polarsを用いたデータ分析の一助となれば幸いです。