こんにちは、SREグループの水戸 (@y_310)です。 タクシーアプリ『GO』ではサービスが出力するログの分析基盤としてGrafana Lokiを使用しています。Grafana LokiはLogQLという言語を使って柔軟にログを分析したり集計してメトリクスとして可視化したりすることができるソフトウェアです。(Loki導入にあたってのインフラ視点のお話はこちらを御覧ください)
LogQLはシンプルなシンタックスの言語ですが少し複雑なことをしようとした時になかなか意図した結果が得られず個人的に使い始めた頃は苦労していました。特にログをメトリクス化するクエリを記述した時に頻繁に maximum of series (1000) reached for a single query というエラーにぶち当たり、解決方法が分からず手当たり次第にクエリを書き換えて何とかほしい結果を得るような状況でした。
こういったLogQLの難しさはLokiがログデータをどういう概念で扱っているのかを理解していなかったことが主な原因で、ある程度そのデータ構造が理解できるとスムーズにクエリが書けるようになりました。
今回は既にLokiのクエリを書いたことがありつつも仕組みが分からない、雰囲気で書いているという方に向けて、Lokiのデータ構造を理解してLogQLを書く方法について解説したいと思います。なお、Lokiの画面の使い方やLokiで使える様々なオペレータ、関数の個々の機能は公式ドキュメントを見る方が網羅的で正確なためこの記事では扱いません。
LogQLの基本構造
LogQLにはまず大きく分けてログクエリとメトリッククエリの二種類があります。ログクエリはログを検索し必要なログだけを抽出するためのクエリです。メトリッククエリはログクエリの結果を元に時系列で集計しメトリクスを生成するためのクエリとなります。
ログクエリ
まずは全ての基礎となるログクエリについて解説します。ログクエリは以下のような形式になっています。前半の {}で囲われた部分がstream selector、その後に続く部分がlog pipelineと呼ばれています。
{cluster="eks-001", pod="app-001"} |= `error` | json | status >= 500 | line_format "{{.path}} {{.status}}"
log pipelineは更にline filter、label filter、parser、line format、label formatなどの式で構成されており、それぞれの式をパイプでつなぐことで左から右に順番に処理されていきます。
この例であれば
- stream selectorの部分で
cluster="eks-001", pod="app-001"にマッチするログに絞り込む - ログに
errorを含むものに更に絞り込む - ログ本文をjsonパースする
- パースした結果の中にある
statusというlabelが500以上のものに絞り込む - パースした結果を使って出力形式を
パス ステータスコードの形に変換する
という処理によって最終的に抽出されたログを出力します。
この時点でstream、line、labelという言葉が出てきました。これらの言葉の意味を理解することがLogQLを理解する上で重要なポイントのため順番に解説していきます。
label
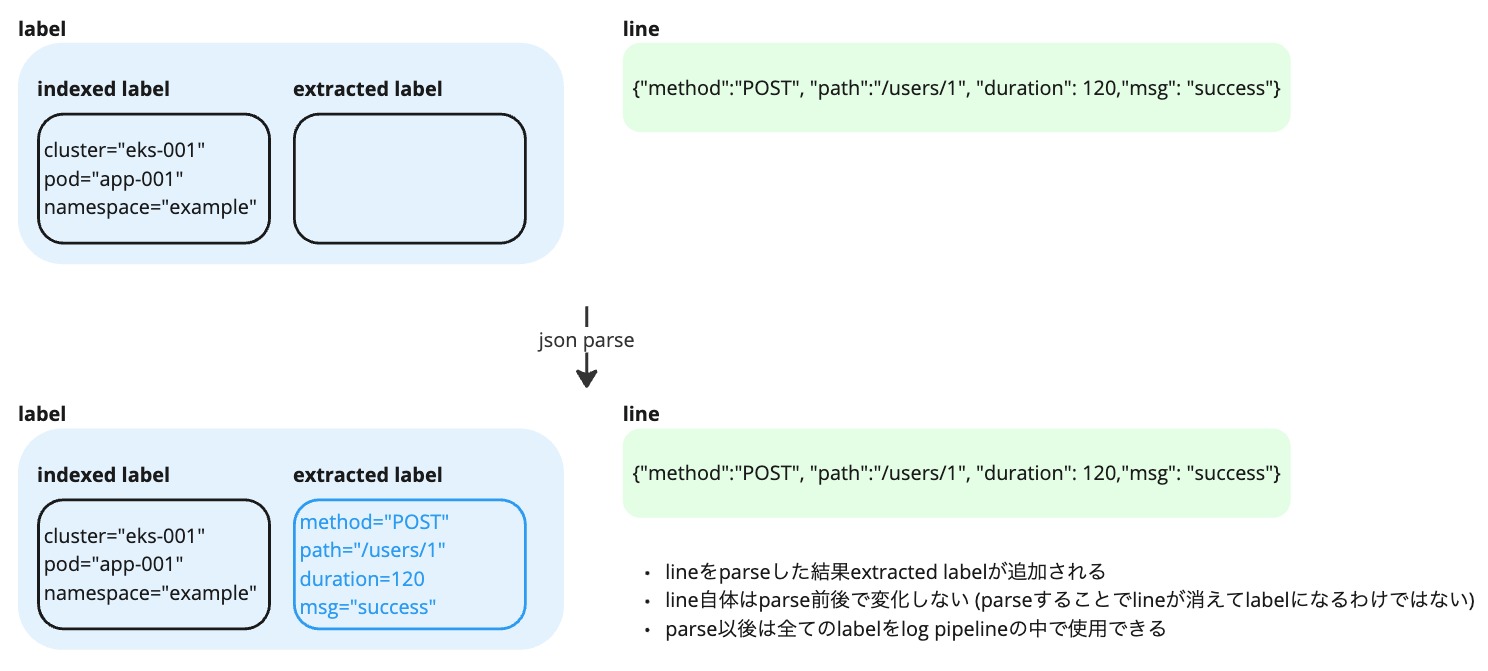
labelがLokiを理解する上で特に重要な要素のためまず最初に解説します。labelはログ1行毎に付与されているkey-value形式のメタデータです。前述の例であればログが発生したKubernetesのクラスタ名やPod名、他にもアプリケーション名やネームスペース名など任意の数のlabelを送信側が予め付与する形でLokiに送信することができます。この予め付与したlabelはindexed labelと呼ばれ、その名の通りLokiによって予めインデックス化され高速にフィルタすることができるようになっています。stream selectorではindexed labelのみ使用できます。
またlabelにはもう一つextracted labelというものが存在します。json parserのようにログ本文をパースするとkey-valueの値が生成されます。これがextracted labelというログから実行時に動的に生成されるlabelでこれを使うことでログ本文に含まれる特定のフィールドに対する検索が行えるようになります。
indexed labelもextracted labelも一度label化されれば以後は区別すること無く同じように扱うことができます。(ただし前述のようにstream selectorで使えるのはindexed labelのみです)
line
lineはアプリケーションが出力したログそのものです。基本的に改行区切りで1行のログが1つのlineに相当します。line自体はただの文字列のため構造化されておらず、検索するにはgrepコマンドのようにマッチする文字列のパターンを指定する形になります。lineをparserによってパースすることでlabelを抽出することができます。
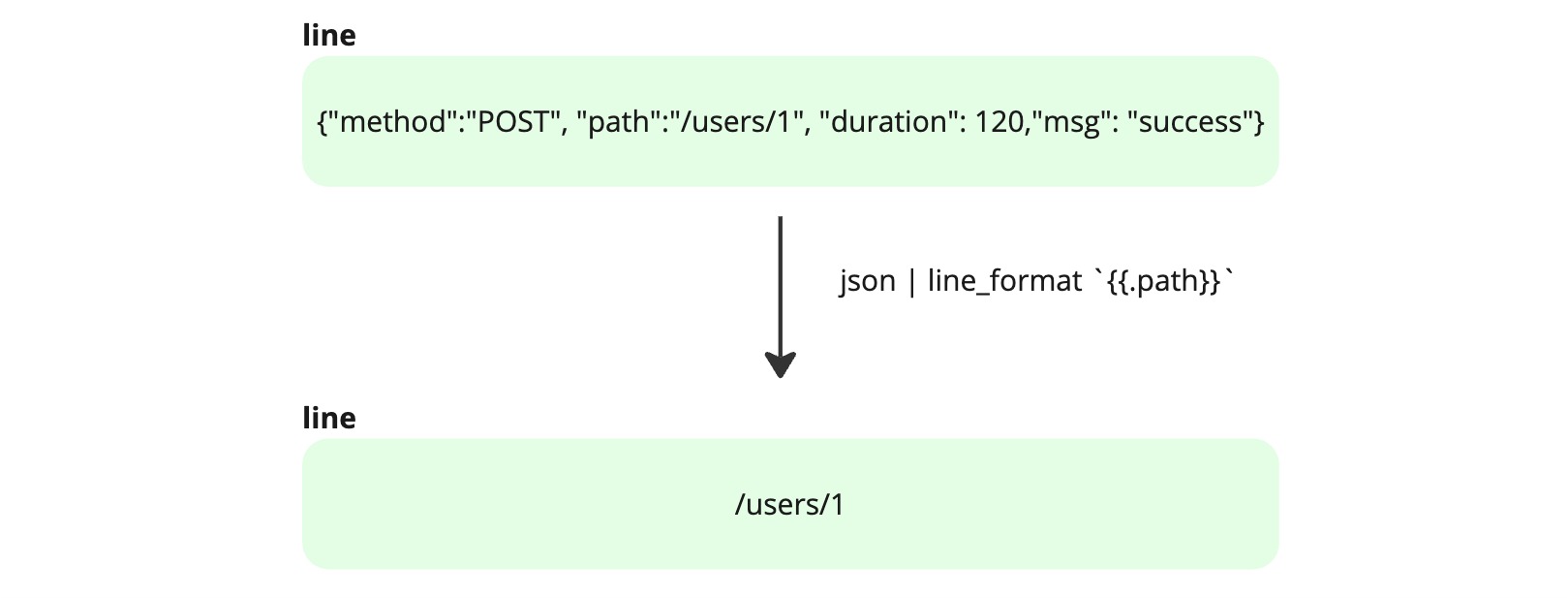
なおlineをパースしてもline自体は変化しません。あくまでパースした結果得られたlabelがextracted labelとして追加されるだけです。line自体を編集したい場合は line_format を使います。line_format は最終的に表示される文字列の見た目を調整することに使用することが多いですが、本質的にはlineのデータを編集する関数です。そのためパイプラインの途中で line_format によってlineを編集し、その後にパースすることでlabelに追加する値を意図した形に調整するといった使い方も可能です。
stream
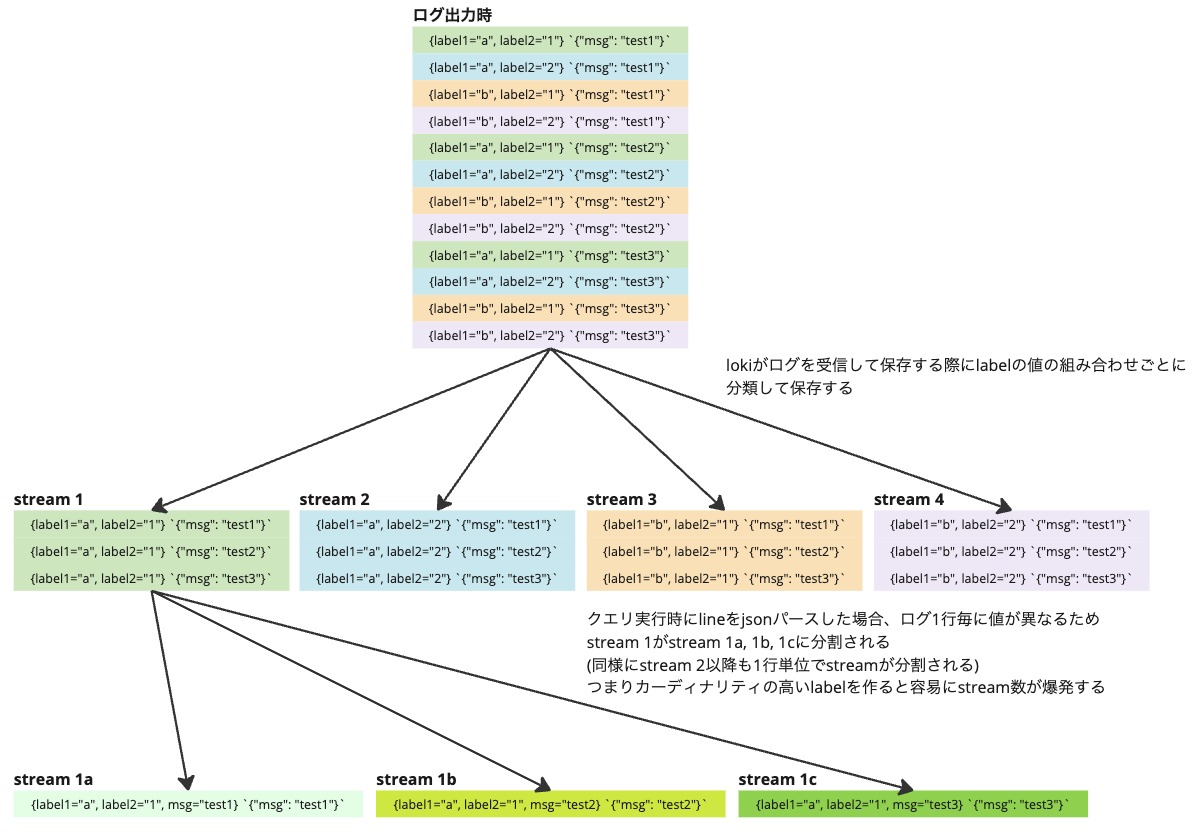
streamはlabelやlineと違ってlokiの画面上明示的には見えませんが内部的に保持されているデータ構造になります。streamはログの集合でlabelの値の組み合わせ1つに対して1 streamが生まれます。例えば値a、bのいずれかを含むlabel1と値1、2のいずれかを含むlabel2がある場合、a-1, a-2, b-1, b-2の4パターンの組み合わせが生まれるため4 stream生まれることになります。streamを構成するlabelはindexed labelだけでなくextracted labelも含むため、json parseした後などはlabelが一気に増加し組み合わせも膨大な数に膨れ上がることになります。
streamはログクエリの場合はあまり意識する必要がない概念ですが後述するメトリッククエリを書く際に重要になります。
ログクエリの振り返り
以上の理解を元に改めて先程のクエリが何をしているのかを説明したいと思います。
{cluster="eks-001", pod="app-001"} |= `error` | json | status >= 500 | line_format "{{.path}} {{.status}}"
- stream selectorによってindexed labelの組み合わせによって生まれたstreamの中から
{cluster="eks-001", pod="app-001"}に該当するstreamを抽出する - line filterによってlineを検索し error という文字列を含むログを抽出する
- lineをjson形式としてパースする。その結果としてlabelの集合にstatus, pathなどのextracted labelが追加される
- label filterによってstatus labelの値が500以上のログを抽出する
- line_formatによってlineの値が
"{{.path}} {{.status}}"に上書きされる
このようにログ1行毎に常にlabelとlineというデータがあり、またそれぞれがパイプラインの中で徐々に変化しながら処理されていくことを理解するとLogQLのクエリを気軽に書けるようになるのではないかと思います。ここまでで大量のログから目的のログを抽出するためのクエリであるログクエリの解説は終わりになります。次はこの抽出したログを集計しメトリクス化するためのメトリッククエリについて解説します。
メトリッククエリ
メトリッククエリはログクエリによって抽出したログから秒間ログ数を計算したり、ログの特定のlabelの値を用いて平均値や最大値などの計算をし時系列の数値データとして出力するクエリです。これによって例えばAPIの秒間リクエスト数やレスポンスタイムなどを計算して可視化することができます。メトリッククエリはログを集計するためのrange vector aggregation関数によって構成されています。またrange vector aggregation関数は計算に使う値によってLog range aggregationとUnwrapped range aggregationに分かれています。
Log range aggregation
Log range aggregationはrateやcount_over_timeなどのログの発生件数に対して集計した数値を出力する関数です。
例えば以下のクエリは5分のウィンドウでログクエリにマッチするログの件数をカウントした数値を出力します。
count_over_time({cluster="eks-001", pod="app-001"} |= `error` [5m])
Unwrapped range aggregation
Unwrapped range aggregationは特定のlabelの値を抽出し、その値に対して集計した数値を出力する関数です。
例えば以下のクエリはdurationラベルの値に対して5分のウィンドウで平均値を計算した結果を出力します。
avg_over_time({cluster="eks-001", pod="app-001"} | json | unwrap duration [5m])
このaggregationでは計算に使うlabelをunwrapで指定します。unwrapに渡したlabelの値が数値として解釈されavg_over_timeによって平均値が計算されます。 なお一度unwrapを呼ぶとlog pipelineの戻り値が変化するようで以後はlineにアクセスできなくなりlabel filterのみ使える状態になるようです。
stream数の爆発とaggregation operatorによる解決
ここで実際にこれらのメトリッククエリを実行してみるとログの内容に依存しますが1本ではなく大量の系列が現れることがあります。またはmaximum of series (500) reached for a single queryというエラーが発生するかもしれません。単純にログ件数をカウントしたり平均値を計算したりするのであれば1系列しか出力されないように思いますが、なぜ複数の系列が出てくるのでしょうか?ここで前述のstreamが関わってきます。
実はrange vector aggregation関数はログをstream単位で計算します。streamはlabelの値の組み合わせの数だけ生成されるため、組み合わせが10個あれば10 stream生成されクエリの結果も10本の系列になります。
labelが大量にあり値の組み合わせが膨大になると系列も同様に膨大に生成されてしまいます。当然それは計算負荷につながるためLokiでは一定以上のstreamが発生するようなクエリは maximum of series (500) reached for a single query というエラーを返して中断します (500という上限は max_query_series という設定で変更できます)。
カーディナリティの高いlabelがあると容易に500以上のstreamができてしまうためjsonパースをした後などは高確率でstream数の上限にあたってしまい結果が得られません。
この問題に対処するためにはstream数を削減する必要があります。そのための方法としてaggregation operatorというstreamを指定した演算で集約する方法が用意されています。aggregation operatorはSQLのGROUP BYのようなもので、指定したlabelを元に結果を集計します。 aggregation operatorはsum、avg、min、maxなどが用意されているので目的に応じた集約方法を選択します。
例えばLog range aggregationで使用したクエリに対してPod単位で集約した結果を得たい場合は以下のクエリになります。
sum by(pod) (count_over_time({cluster="eks-001"} |= `error` [5m]))
このクエリはstreamをPodの数に集約し、ログ発生件数をPod単位で合計した数値を出力します。そのため10 Podのログであれば10系列の出力が得られます。
なお、Pod数が500を超えていると集約しても500 stream以上になってしまうためmaximum of series (500) reached for a single queryが発生します。その場合はフィルタ条件を追加して参照期間内にログを出力したPodの数が500以下になるようにするなどの調整が必要になります(検索期間を短縮する、Podが存在するゾーンを絞るなど)
LogQLのクエリ例
最後にここまでで紹介した知識を使って少し複雑なクエリの例を解説します。 ここでは以下のログを処理するクエリを紹介します。
{ "req_method": "GET", "path": "/users/1", "response_code": 200, "start_time": "2024-11-22T10:00:00.000Z", "duration": 131 } { "req_method": "GET", "path": "/users?name=alice", "response_code": 200, "start_time": "2024-11-23T10:00:00.000Z", "duration": 432 }
それぞれのログには {app="example"} というindexed labelが付与されていることとします。
上記の形式のログに対してAPIパスごとのリクエスト数の合計を計算するのが以下のクエリになります。
sum by(canonical_path) (
count_over_time(
{app="example"}
| json
| line_format `{{.path}}`
| line_format `{{regexReplaceAll "\\?.+" __line__ ""}}`
| line_format `{{regexReplaceAll "/\\d+" __line__ "/:id"}}`
| line_format `canonical_path={{__line__}}`
| logfmt
[$__auto]
)
)
このクエリにおいてのポイントは複数回line_formatを呼んでいる部分です。APIパスごとの集計をするにあたりIDの数字やクエリパラメータをそのまま扱うと同じAPIであってもパラメータが異なるだけで異なるstreamになってしまいます。そのため同一のAPIのリクエストをパラメータ等に左右されず集計させるために、line_formatを使ってパス文字列を整形しています。
- 1つ目のline_format: lineをpathラベルの値に変換 (これによりlineの値が
{"req_method": "GET",...}から/users/1のようなpathだけの文字列に変化する) - 2つ目のline_format: lineの?以降の文字列を空文字に置換 (
/users?name=aliceを/usersに変換) - 3つ目のline_format: lineの
/数字を/:idという文字列に置換 (/users/1を/users/:idに変換) - 4つ目のline_format: 新しいlabelの生成準備としてlineを
canonical_path=/usersやcanonical_path=/users/:idに変換 - logfmtによって
canonical_pathというextracted labelを追加
このように徐々にlineの値を変換することで最終的にAPIパスを正規化し最終的にextracted label化しています。
最後に生成したcanonical_path labelを使ってsumでstreamを集約してパスごとのリクエスト数の数字を得ることができます。
最後に
LogQLを理解するためには以下の点が重要でした。
- labelとlineの違い
- indexed labelとextracted labelの違い、lineをパースすることでextracted labelに追加されること
- lineをパースしてもline自体は変化せず、lineを変更したい場合はline_formatによって編集できること
- streamはlabelの値の組み合わせの数だけ生成されること、extracted labelもstreamに影響すること
LogQLの全てを解説できたわけではありませんが、これらを理解することでLogQLのコンセプトの重要な部分については把握できるかと思います。 この情報で少しでも思い通りにログ調査ができるようになれば幸いです。