高速マッチングを実現する!二部グラフの最大重みマッチングとその解法
こんにちは!AI技術開発部の木村彩恵です。
業務では、タクシーアプリ『GO』の中核技術である、乗客からのリクエストに対し配車するタクシーを決定するマッチングエンジンの開発に携わっています。 タクシーアプリ『GO』のマッチングエンジンでは、マッチングの全体最適を実現するために、一つ一つのリクエストに対して都度タクシーを決定するのではなく、一定周期ごとに複数のリクエストに対して一括でタクシーを決定します。 このとき、迎車時間などのリクエストとタクシー間の様々な条件を重みつき二部グラフで表現し、最大重みマッチング問題を解くことでマッチングを実現しています。
本記事では、二部グラフの最大重みマッチング問題の基本的な概念から、最大重みマッチング問題の様々な定式化について紹介します。
二部グラフとマッチングの基礎
グラフの基本
グラフは、頂点集合と辺集合から構成されます。頂点集合を 、辺集合を
としたとき、グラフ
で表記します。
また頂点
と
が辺
で結ばれている場合、隣接するといい、
と
を辺
の端点と呼びます。
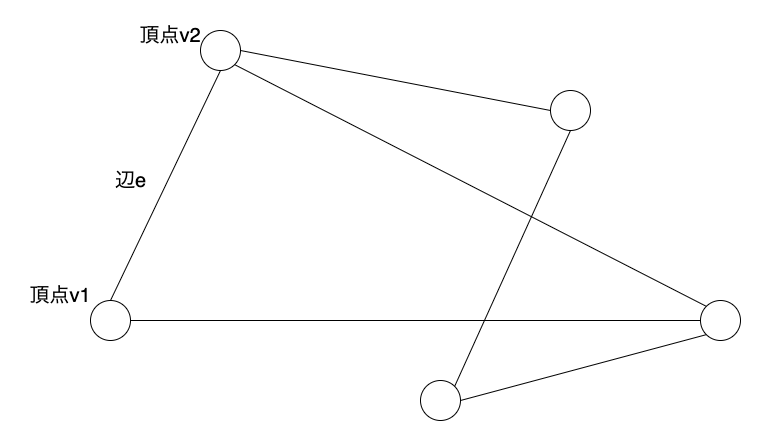
二部グラフ
二部グラフとは、グラフ の頂点集合を
と
の二つの集合に分割でき、
に属する頂点同士、あるいは
に属する頂点同士が隣接しないグラフのことです。
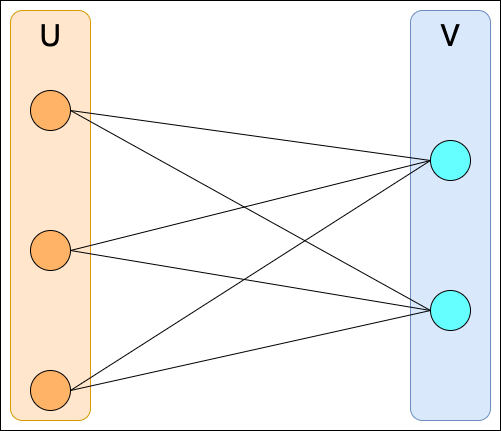
マッチングの種類
グラフ の辺集合
の部分集合
において、
に含まれるどの2つの辺も端点を共有しないとき、
をマッチングと呼びます。
マッチングにはいくつかの種類があります。
- 最大マッチング:辺の本数が最大のマッチング
- 完全マッチング:どの頂点も辺と接続されているマッチング
- 最大(最小)重みマッチング:辺に重みが定義されている場合に、重みの和を最大化(最小化)するマッチング
重みつき二部グラフの最大重みマッチングの応用例
二部グラフの最大重みマッチングは、タクシーアプリ『GO』のようなタクシー配車を決定する問題以外にも、様々な分野で応用されています。 例えば、デジタル広告の分野において、Googleなどの広告在庫管理システムでは、 将来発生する膨大な広告表示機会(インプレッション)を、どの広告主に、いつ、どれだけ割り当てるかを最適化 する問題を二部グラフの最大重みマッチングとして扱います(文献1)。 また、バイオインフォマティクスの分野では、タンパク質の構造比較や重ね合わせにおいて二部グラフの最大重みマッチングが使われています(文献2)。
最大重みマッチング問題の解法
線形計画問題として解く
まず、最大重みマッチング問題は、変数 を「頂点
、
を結ぶ辺
を選ぶか(1)否か(0)」を決める整数計画問題として定式化されます。
ただし、
は辺
の重みとします。
- 目的関数:
- マッチング制約:各頂点について接続する辺は高々1つだけマッチングに含まれる
- 整数制約:変数
は二値(整数)である
整数計画問題は計算が困難な問題(NP困難)です。
しかし、二部グラフの最大重みマッチングでは、変数の整数制約 を
に線形緩和した線形計画問題の最適解が必ず整数になるという性質(全ユニモジュラ性)があります。
このため、単体法などの解法で比較的高速に解くことができます。
pulpによる実装例は次の通りです。
import pulp def max_weight_matching_lp(weights: np.ndarray): edges = [] for i in range(0, weights.shape[0]): for j in range(0, weights.shape[1]): edges.append((i , j, weights[i][j])) # PuLPの問題を作成 prob = pulp.LpProblem("MaximumWeightMatching", pulp.LpMaximize) # 変数:辺ごとに選択されるかどうかを保持(線形緩和版) variables = {(u, v): pulp.LpVariable(f"x_{u}_{v}", lowBound=0) for u, v, w in edges} # 目的関数:辺の重みの合計を最大化 prob += pulp.lpSum(variables[u, v] * w for u, v, w in edges) # 制約:各頂点は高々1つの辺と接続する for u in set(u1 for u1, v1, w1 in edges): prob += pulp.lpSum(variables[u, v] for v in set(v2 for u2, v2, w2 in edges if u == u2)) <= 1 for v in set(v1 for u1, v1, w1 in edges): prob += pulp.lpSum(variables[u, v] for u in set(u2 for u2, v2, w2 in edges if v == v2)) <= 1 # ソルバの設定 solver = pulp.COIN_CMD(path='/opt/homebrew/bin/clp') # 問題を解く prob.solve(solver) # マッチング結果を抽出 row_ind = [] col_ind = [] for v in prob.variables(): if v.varValue > 0: # 変数名から行と列のインデックスを抽出 (x_i_j形式) parts = v.name.split('_') row_idx = int(parts[1]) col_idx = int(parts[2]) row_ind.append(row_idx) col_ind.append(col_idx) matches = list(zip(row_ind, col_ind)) return matches
最小費用流問題として解く
次に、マッチングを「モノの流れ」として捉え、ネットワークフローの最適化問題(最小費用流問題)として解く方法を紹介します。
ネットワークフローの最適化問題では、ネットワーク と呼ばれる有向グラフの ソース(始点) から シンク(終点) まで何かを流す問題を扱います。 このとき、以下の2つの制約を満たす必要があります。
- 容量制限: 全ての辺において、フローは容量以下である
- フロー保存則:ソースとシンクを除く全ての頂点において、流入量の合計と流出量の合計は同じ
最小費用流問題は、ソースからの流出量と各辺の容量、単位フロー当たりの費用が与えられた場合に、総費用を最小化する流し方を決める問題です。容量スケーリング法などの解法で解くことができます。
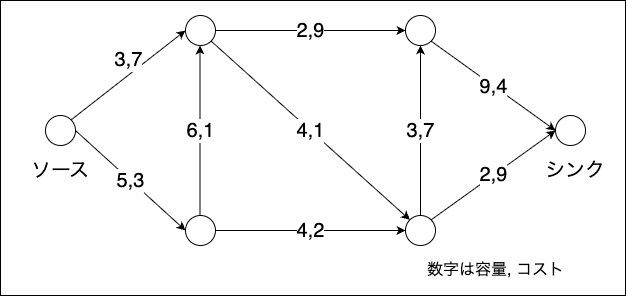
最小費用流問題の例
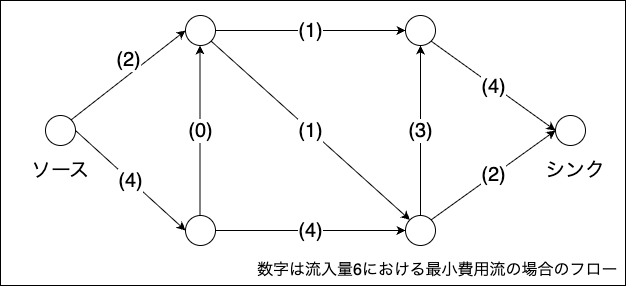
最小費用流問題の例の最適解
二部グラフの最大重みマッチング問題は、以下の手順に従って最小費用流問題に帰着できます。
- 二部グラフにソースとシンクを追加し、ソースと頂点集合
の全ての頂点間および、頂点集合
の全ての頂点とシンク間に辺を追加します。辺の容量は1、費用は0とします。
- 頂点集合UとVの頂点間の辺は容量を1、費用は重みを反転させた(-1をかけた)値とします。
- ソースからの流入量を、
とします。
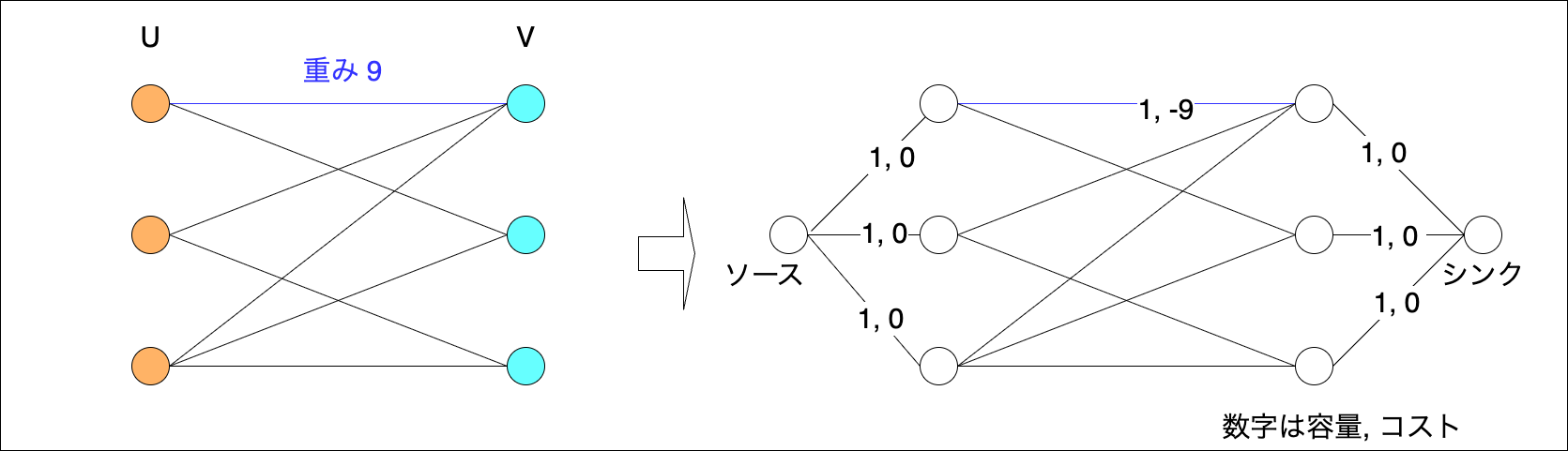
Networkxによる実装例は次の通りです。
import networkx as nx def max_wight_matching_network_flow(weights: np.ndarray): # 最小費用流問題のグラフを作成 G = nx.DiGraph() # ソースの追加 G.add_node("S", demand = -1 * weights.shape[0]) # シンクの追加 G.add_node("T", demand = weights.shape[0]) # ソースから頂点集合Uまでの辺の追加 for i in range(0, weights.shape[0]): G.add_edge('S', 'U_'+str(i), capacity=1, weight=0) # 頂点集合Uから頂点集合Vへの辺の追加 for i in range(0, weights.shape[0]): for j in range(0, weights.shape[1]): if weights[i][j] > 0: G.add_edge('U_'+str(i), 'V_'+str(j), capacity= 1, weight= -1 * int(weights[i][j])) # 頂点集合Vからシンクまでの辺の追加 for j in range(0, weights.shape[1]): G.add_edge('V_'+str(j), 'T', capacity=1, weight=0) # 最小費用でのフローを計算 flow_dict = nx.min_cost_flow(G) # マッチング結果を抽出 row_ind = [] col_ind = [] for source, dests in flow_dict.items(): for dest, flow in dests.items(): sources = source.split("_") dests_split = dest.split("_") if int(flow) > 0 and source != "S" and dest != "T": row_idx = int(sources[1]) col_idx = int(dests_split[1]) row_ind.append(row_idx) col_ind.append(col_idx) matches = list(zip(row_ind, col_ind)) return matches
最小重み完全マッチング問題として解く
最後に、二部グラフの最小重み完全マッチング問題に特化した、多項式時間で解くことができるアルゴリズム(ハンガリー法やJonker-Volgenant法)を利用する方法を紹介します。
これらのアルゴリズムでは、ある頂点のすべての辺に同じ値を加算しても解に影響を与えないという特性を利用し、各頂点に接続された辺のうち、重み0の辺が一つ以上存在するような問題に変換し、重み0の辺だけで完全マッチングを求めることで、最小重み完全マッチング問題を解きます。
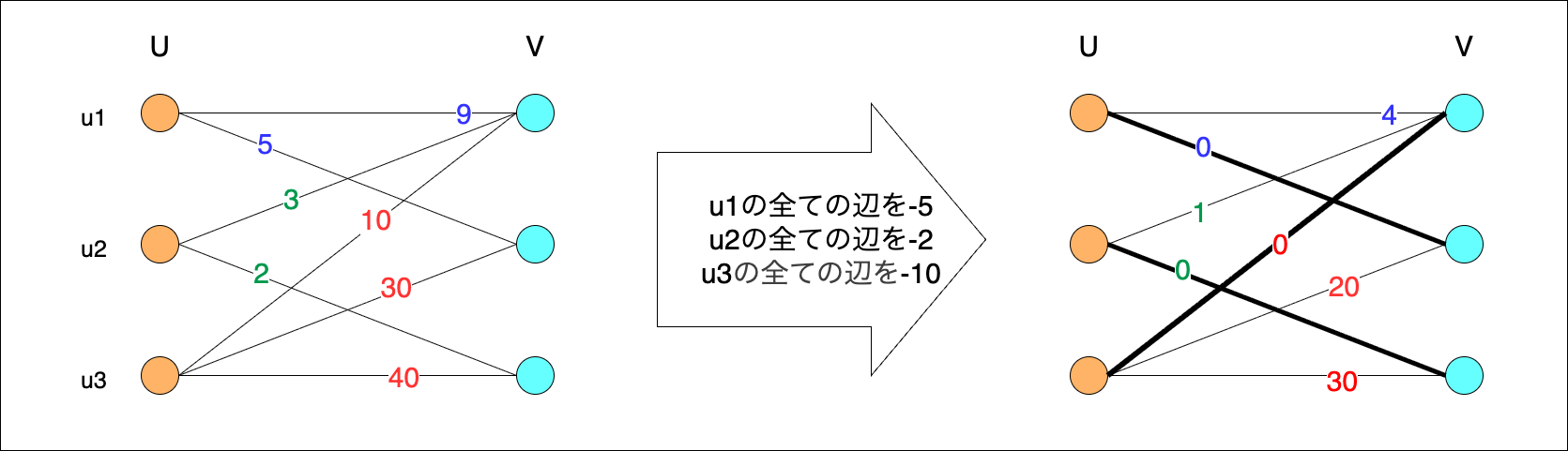
二部グラフの最大重みマッチング問題は、重みを反転させることで最小重み完全マッチング問題に帰着できます。
SciPyによる実装例(Jonker-Volgenant法)は次の通りです。
from scipy.optimize import linear_sum_assignment def max_weight_matching_jv(weights: np.ndarray): # 最大重みマッチングから最小重みマッチングへの変換 cost_matrix = weights.max() - weights # 最小重みマッチングを解く row_ind, col_ind = linear_sum_assignment(weights) matches = list(zip(row_ind, col_ind)) return matches
定式化が実行時間に与える影響
実行速度を比較するために、頂点集合 のサイズを50、頂点集合
のサイズを200とし、辺の重みの密度(非ゼロ割合)ごとの、平均実行時間(M4 Mac、シミュレーション30回)を計測しました。
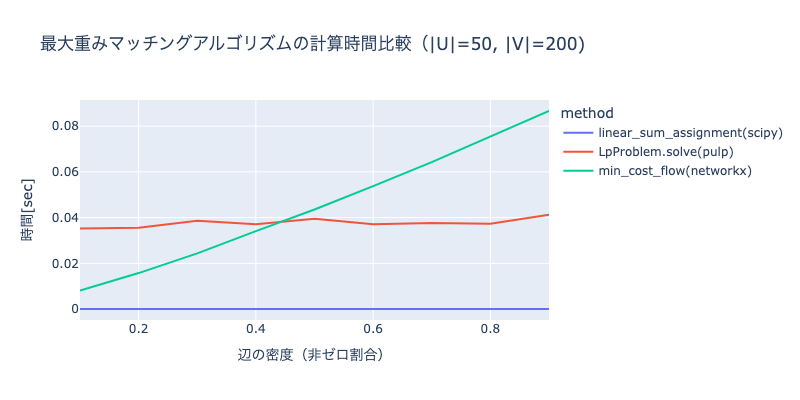
使用しているライブラリが異なるため、定式化の差だけではなく、実装の違いによる影響も大きいですが、以下のことがわかります。
- 最小重み完全マッチング問題として解いた場合(linear_sum_assignment)、密度によらず常に最速であり、大規模・高密度な問題でも安定したパフォーマンスを発揮します。実際にタクシーアプリ『GO』のマッチングエンジンでもこの手法を採用しており、リアルタイム性の高い配車マッチングを実現しています。
- 最小費用流として解いた場合(min_cost_flow)、密度が高くなる(辺の数
が増える)ほど実行時間が増加しています。これは、グラフ特有の構造を利用しており、計算量が辺の数に依存するためです。
- 一方で線形計画問題として解いた場合(LpProblem)、密度の影響をほとんど受けません。これは単体法などの汎用ソルバーにおいて、計算コストが辺の数よりも変数や制約式の数に依存するためです。
このように、同じ最適化問題であっても、グラフの規模やグラフの密度といった問題の性質や、多項式時間で解けるアルゴリズムの有無を考慮して、最適な定式化を選択することが重要です。
まとめ
本記事では、二部グラフの最大重みマッチングの概要と、3つの定式化を紹介しました。 定式化次第で、表現できる問題の柔軟性や実行速度が変わる点は最適化問題のとても面白いところだと思います。
最後まで読んでいただき、ありがとうございました。